
Le vrai danger de l'IA : ses failles, pas sa malveillance
Les principaux enjeux de sécurité de l'IA découlent d'erreurs, et non d'intentions malveillantes. Cet article explore pourquoi ce sont ces failles, et non une quelconque malveillance, qui peuvent avoir des conséquences considérables.
Les véritables défis en matière de sécurité de l’IA : au-delà des robots tueurs
Les principaux défis en matière de sécurité de l’IA proviennent d’erreurs, et non d’intentions malveillantes. La sécurité de l’IA n’est pas un concept futuriste. Elle a déjà un impact sur la vie quotidienne de manière subtile mais grave. Nous ne parlons pas d’une IA qui deviendrait maléfique. Nous parlons d’une IA qui commet des erreurs aux conséquences énormes.
Imaginez la construction d’un pont. Vous ne craignez pas qu’il s’effondre par malveillance. Vous vous inquiétez plutôt des défauts de conception, des défaillances des matériaux ou des contraintes inattendues. Ce sont ces éléments qui le rendent peu fiable et dangereux. Il en va de même pour l’IA. Ses défaillances proviennent d’interactions inattendues, de données d’entraînement biaisées ou simplement du fait qu’elle ne fonctionne pas comme prévu dans le monde réel.
Les failles cachées de l’IA
Le 18 mars 2018, un véhicule d’essai Uber autonome a heurté et tué Elaine Herzberg à Tempe, en Arizona. Cet incident tragique a mis en évidence un problème fondamental. Les systèmes d’IA, même les plus avancés, peuvent échouer dans des scénarios complexes du monde réel. Le logiciel du véhicule a d’abord classé Herzberg comme une cycliste. Puis, il l’a qualifiée d’objet inconnu, ne parvenant pas à prédire correctement sa trajectoire.
La fiabilité de l’IA signifie qu’un système d’IA exécute constamment la fonction pour laquelle il a été conçu dans des conditions variées. Elle repose sur la prévisibilité et la cohérence. La sécurité de l’IA, en revanche, vise à prévenir les dommages. Cela inclut les blessures physiques, les pertes financières ou la discrimination injustifiée. Un système peut même être fiable dans la constance de ses erreurs, par exemple en prenant constamment des décisions biaisées.
Pourquoi l’IA se trompe
Les systèmes d’IA apprennent à partir de schémas présents dans de vastes quantités de données. Ce processus d’apprentissage est à l’origine de nombreux problèmes de sécurité et de fiabilité. Si les données sont défectueuses, l’IA hérite de ces défauts.
En 2018, les chercheuses Joy Buolamwini et Timnit Gebru ont publié l’étude “Gender Shades” du MIT Media Lab. Elles ont montré que les systèmes de reconnaissance faciale des grandes entreprises technologiques présentaient des taux d’erreur nettement plus élevés pour les femmes à la peau foncée, comparativement aux hommes à la peau plus claire. Cela était dû au biais de données : les ensembles de données d’entraînement contenaient moins d’images de visages variés. L’IA a appris à reconnaître certains groupes démographiques mieux que d’autres.
Un autre défi est le manque d’explicabilité, souvent appelé le “problème de la boîte noire”. Les modèles d’IA complexes, en particulier les systèmes d’apprentissage avancés, prennent des décisions de manière opaque pour les humains. Nous voyons les entrées et les sorties, mais il est difficile de retracer les étapes intermédiaires. La Defense Advanced Research Projects Agency (DARPA) a lancé son programme Explainable AI (XAI) pour y remédier. L’objectif est de créer des systèmes d’IA capables d’expliquer leur raisonnement, leur fiabilité et leurs implications.

Le 18 mars 2018, un véhicule d'essai Uber autonome, un Volvo XC90 modifié, a heurté et tué Elaine Herzberg à Tempe, en Arizona. Cet incident tragique a mis en évidence les défis critiques en matière de sécurité des systèmes autonomes opérant dans des scénarios complexes du monde réel, démontrant comment les erreurs de l'IA peuvent avoir des conséquences dévastatrices. (Source: theverge.com)
Les systèmes d’IA peuvent également être vulnérables aux entrées manipulées. Il s’agit de changements subtils, souvent imperceptibles, apportés aux données d’entrée, conçus pour tromper une IA. Une étude de 2014 co-écrite par Ian Goodfellow l’a démontré. L’ajout d’un bruit minuscule et spécifiquement conçu à l’image d’un panda pouvait amener un système d’apprentissage à le classer comme un gibbon avec un haut degré de confiance. Cela révèle un manque de résilience. L’IA peut être facilement trompée par des entrées qui ne correspondent pas à sa distribution d’entraînement habituelle. De telles vulnérabilités compromettent les systèmes de conduite autonome ou les systèmes de sécurité.
Les risques réels d’une IA peu fiable
Une IA peu fiable ou dangereuse a des conséquences réelles ; ces risques se matérialisent dans des secteurs critiques. En 2016, ProPublica a enquêté sur l’algorithme COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) utilisé dans les tribunaux américains. L’enquête a révélé qu’il était deux fois plus susceptible de signaler à tort des accusés noirs comme de futurs criminels, comparativement aux accusés blancs. Inversement, il signalait à tort des accusés blancs comme présentant un faible risque plus souvent que les accusés noirs. Ceci illustre comment les biais inhérents aux règles du système peuvent perpétuer et amplifier les inégalités sociétales existantes au sein du système judiciaire.
Dans le domaine de la santé, l’IA promet des avancées mais aussi des risques. Les premières versions d’IBM Watson Health, par exemple, ont fait l’objet de critiques. Le système a fourni des recommandations de traitement du cancer dangereuses et erronées. Un rapport de STAT News de 2018 a détaillé des cas où des médecins ont jugé les recommandations de l’IA “extrêmement imprécises” ou potentiellement dangereuses. Cela était en partie dû à des données d’entraînement limitées et à une dépendance excessive à des cas de patients hypothétiques. Cela souligne la nécessité de tests et de validations rigoureux avant de déployer l’IA dans des applications vitales.
Les systèmes autonomes, des véhicules aux drones, présentent des risques directs pour la sécurité physique. Au-delà de l’incident Uber, la prédiction du comportement humain et des variables environnementales reste un défi majeur. Même de petites erreurs de perception ou de prise de décision peuvent être fatales. C’est comparable à un chirurgien expérimenté utilisant des instruments défectueux. L’expertise existe, mais les outils font défaut.
Construire une IA plus sûre : ce que nous faisons
Aborder la fiabilité et la sécurité de l’IA nécessite une approche à plusieurs volets. Cela implique l’innovation technique, les politiques et les considérations éthiques. L’Union européenne mène cet effort, en adoptant l’EU AI Act en mars 2024. Cette réglementation historique classe les systèmes d’IA en fonction de leur niveau de risque. Elle impose des exigences strictes aux applications “à haut risque” comme celles utilisées dans les infrastructures critiques, les soins de santé ou le maintien de l’ordre. Ces exigences comprennent la gestion des données, la supervision humaine, la transparence et les évaluations de conformité.

Le Parlement européen à Bruxelles, en Belgique, est le lieu où l'historique EU AI Act a été adopté en mars 2024. Cette réglementation révolutionnaire est la première loi complète au monde sur l'intelligence artificielle, visant à garantir la sécurité et la fiabilité des systèmes d'IA dans divers secteurs. (Source: gettyimages.ca)
Techniquement, nous travaillons à améliorer l’IA explicable (XAI). Des chercheurs comme Cynthia Rudin de l’Université Duke préconisent des modèles intrinsèquement interprétables. Ceux-ci sont préférables aux explications a posteriori des systèmes dits “boîte noire”. Ces modèles sont conçus dès le départ pour être compréhensibles. Cela facilite l’identification et la correction des erreurs. Par exemple, une IA médicale pourrait non seulement prédire un diagnostic, mais aussi mettre en évidence les symptômes spécifiques et les antécédents médicaux du patient qui ont mené à sa conclusion.
Les tests de résilience deviennent une pratique courante. Cela implique de réaliser activement des tests de sécurité proactifs sur les systèmes d’IA. Les experts essaient intentionnellement de trouver des failles et de les “mettre en défaut”, souvent en utilisant des entrées manipulées. Cela aide les développeurs à identifier les vulnérabilités avant le déploiement. Des organisations comme le National Institute of Standards and Technology (NIST) ont développé des cadres. Un exemple est le NIST AI Risk Management Framework. Ces cadres guident les développeurs dans la gestion des risques liés à l’IA tout au long de son cycle de vie. Ce cadre met l’accent sur la transparence, la validation et la responsabilité.
Enfin, la supervision humaine reste vitale, surtout dans les applications à forts enjeux. Il ne s’agit pas de confier aux humains le travail de l’IA. Il s’agit d’assurer une supervision humaine pour la surveillance, l’intervention et la responsabilité ultime. C’est reconnaître que l’IA est un outil puissant. Pourtant, le jugement humain reste essentiel pour un déploiement éthique et sûr. Concevoir un gratte-ciel ne consiste pas seulement à le construire en hauteur. Il s’agit aussi de sa résistance aux tremblements de terre, de la sécurité incendie et des voies d’évacuation.
L’avenir de la sécurité de l’IA
L’IA progresse rapidement, et ses défis en matière de fiabilité et de sécurité ne cessent d’évoluer. En novembre 2023, le Royaume-Uni a accueilli l’AI Safety Summit à Bletchley Park. Des dirigeants mondiaux s’y sont réunis pour discuter des risques liés à l’IA avancée. Bien que cet événement ait mis en évidence un accord international croissant sur la nécessité d’une collaboration, s’accorder sur des normes mondiales et leur mise en œuvre reste une tâche diplomatique complexe.
Un défi persistant consiste à garantir que les mesures de sécurité fonctionnent pour des systèmes plus grands. Les modèles d’IA deviennent plus vastes et plus polyvalents, comme ceux qui sous-tendent les systèmes linguistiques avancés. Leur potentiel de comportements inattendus ou de nouvelles capacités imprévues augmente. Assurer la sécurité de systèmes aussi complexes est un problème bien différent de celui des IA spécialisées et à tâche unique. Le nombre de modes de défaillance potentiels augmente de manière exponentielle.

En novembre 2023, le Royaume-Uni a accueilli le premier grand sommet mondial sur la sécurité de l'IA à Bletchley Park, le site historique où les cryptographes alliés ont déchiffré le code Enigma pendant la Seconde Guerre mondiale. Des dirigeants mondiaux s'y sont réunis pour discuter des risques et de la gouvernance de l'IA avancée, soulignant le consensus international croissant sur la nécessité d'efforts collaboratifs en matière de sécurité. (Source: reuters.com)
Un autre axe est le développement de meilleures méthodes de vérification et de validation des systèmes d’IA. Cela implique la création d’environnements de test rigoureux et de méthodes de test structurées. Ces méthodes prouvent mathématiquement certaines propriétés de sécurité des systèmes d’IA. C’est un domaine hautement technique, mais vital pour garantir que l’IA se comporte de manière prévisible dans des situations critiques. Les chercheurs explorent également comment l’IA peut elle-même devenir plus sûre. Ils utilisent des techniques d’IA pour surveiller, tester et même réparer d’autres systèmes d’IA.
En fin de compte, la sécurité future de l’IA dépend d’une recherche continue, d’une réglementation proactive et d’un engagement mondial en faveur d’un développement responsable. Nous devons dépasser les corrections réactives et intégrer la sécurité dès la phase de conception. Cet effort collectif ne vise pas seulement à prévenir les catastrophes. Il s’agit de façonner l’IA afin d’en faire une force bénéfique, et non une source de préjudice imprévisible.
Foire aux questions
Quelle est la principale idée fausse concernant la sécurité de l’IA ? Beaucoup de gens supposent à tort que la sécurité de l’IA concerne principalement une IA qui deviendrait maléfique et prendrait le contrôle. Le danger réel et actuel réside dans les erreurs subtiles, les biais et les conséquences imprévues au sein des systèmes d’IA. Ces éléments entraînent des dommages ou des résultats inéquitables.
L’IA peut-elle être fiable à 100 % ? Non, atteindre une fiabilité de 100 % pour des systèmes d’IA complexes interagissant avec des environnements réels imprévisibles est pratiquement impossible. Comme toute technologie, l’IA fonctionne avec des limitations inhérentes et des probabilités d’erreur. C’est particulièrement vrai lorsqu’elle est confrontée à des situations nouvelles qui ne figurent pas dans ses données d’entraînement.
Qui est responsable lorsque l’IA commet une erreur ? Déterminer la responsabilité est un défi juridique et éthique complexe. Elle incombe souvent aux développeurs, aux opérateurs ou à ceux qui déploient le système d’IA. Cela dépend de facteurs comme la négligence, les défauts de conception ou l’utilisation abusive. Des réglementations comme l’EU AI Act visent à clarifier cette responsabilité.
Qu’est-ce que l’EU AI Act ? L’EU AI Act est une réglementation pionnière de l’Union européenne. Elle classe les systèmes d’IA en fonction de leur niveau de risque potentiel. Elle impose des exigences strictes aux IA “à haut risque”. Ces exigences mettent l’accent sur la transparence, la supervision humaine, la qualité des données et les évaluations de conformité. L’objectif est de garantir la sécurité et l’utilisation éthique dans tous les États membres.
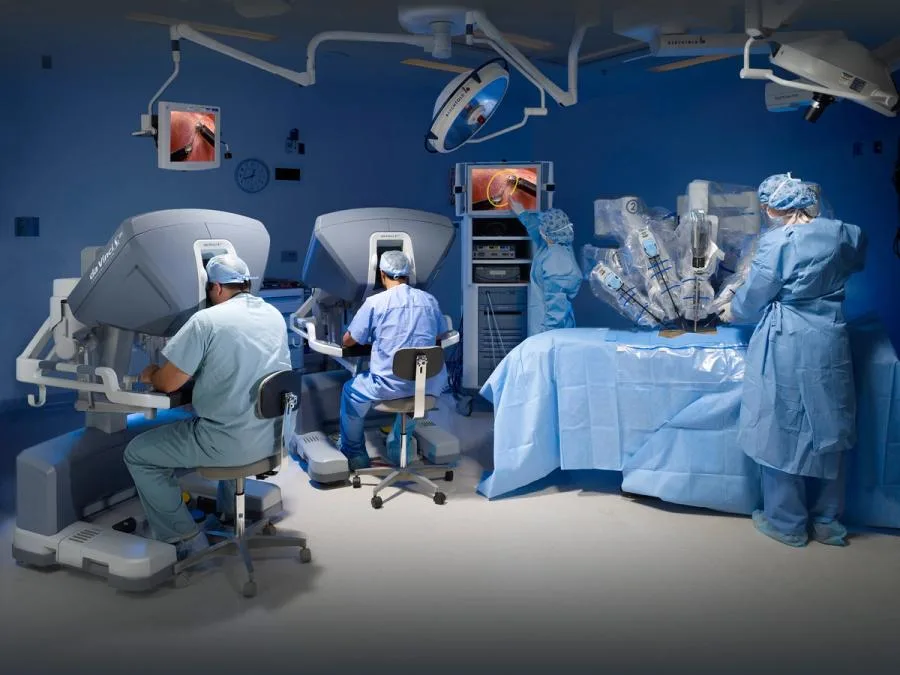
Un robot chirurgical assisté par IA, tel que le système chirurgical da Vinci largement utilisé, illustre une application d'IA "à haut risque" où des tests rigoureux et une preuve mathématique de sécurité sont primordiaux. Ces systèmes complexes nécessitent une supervision méticuleuse pour garantir un fonctionnement prévisible et sûr lors de procédures médicales critiques. (Source: robotsguide.com)
Vous pourriez aussi aimer:
👉 La Révolution Invisible : Explorer la Robotique à travers des Exemples de la Vie Quotidienne
👉 Démasquer les bots en ligne : le défi du mimétisme sur X et Facebook