
Anthropic : le pari d'une IA sûre et éthique depuis 2021
Fondée en 2021 par d'anciens chercheurs d'OpenAI, l'entreprise Anthropic s'est donné pour mission de créer une intelligence artificielle puissante mais intrinsèquement sécurisée. Elle a développé l'approche de l'« IA constitutionnelle » pour son modèle Claude, afin de garantir le respect des valeurs humaines.
Quand la sécurité de l’IA est mise à rude épreuve : le bouclier anti-requêtes d’Anthropic à l’examen
Construire une IA sûre est difficile. Début 2021, une nouvelle entreprise, Anthropic, s’est lancée avec une mission audacieuse. Elle a été fondée par Dario et Daniela Amodei, d’anciens chercheurs d’OpenAI. Leur objectif : créer une IA à la fois puissante et dont la sécurité serait avérée. Leur vision s’articulait autour de l’« IA constitutionnelle ». Cette approche consistait à utiliser des principes directeurs – une « constitution » – afin que les modèles d’IA respectent les valeurs humaines.
Anthropic a commencé à développer Claude, son principal grand modèle linguistique (LLM). Les LLM sont des programmes informatiques complexes. Ils comprennent et génèrent du texte qui reproduit le langage humain. Ces modèles apprennent à partir d’énormes quantités de données issues d’internet.
L’entreprise visait des systèmes qui soient utiles, inoffensifs et honnêtes. Cela nécessitait de solides fonctionnalités de sécurité. L’une d’elles était le bouclier anti-requêtes. Il agit comme un gardien numérique, bloquant les requêtes utilisateur malveillantes. Il empêche également l’IA de générer des réponses dangereuses ou inappropriées.
La sécurité était primordiale. Une IA non filtrée pourrait propager de la désinformation. Elle pourrait également véhiculer des stéréotypes néfastes ou encourager des actions dangereuses. Anthropic savait que les risques étaient immenses. Leur engagement en faveur d’une IA éthique a rapidement attiré l’attention et suscité un examen minutieux.
Comment fonctionne le gardien numérique
Le bouclier anti-requêtes d’Anthropic n’était pas un simple filtre. Il constituait un élément central de leur approche d’IA constitutionnelle. Cette approche enseigne aux modèles d’IA à s’améliorer. Ils apprennent à partir de principes rédigés par des humains. Ces principes préconisent souvent d’éviter les contenus nuisibles. Ils indiquent également à l’IA d’encourager les bonnes interactions.
Le bouclier anti-requêtes vérifie les requêtes des utilisateurs. Il recherche des indices liés à des intentions malveillantes. Il recherche également les tentatives de « jailbreak » de l’IA. Le jailbreak consiste à tenter de contourner les fonctionnalités de sécurité. Ces tentatives visent souvent à faire produire à l’IA du contenu qu’elle est censée refuser.
Supposons qu’un utilisateur demande des instructions pour fabriquer une bombe. Le bouclier anti-requêtes devrait intervenir. Il empêcherait Claude de fournir cette information. Au lieu de cela, il générerait un refus. Ce refus expliquerait pourquoi la requête n’a pas pu être satisfaite.
Le bouclier vérifie également les réponses potentielles de l’IA elle-même. Il agit comme une deuxième ligne de défense. Cela garantit qu’une réponse générée reste sûre, même si une requête astucieuse parvient à passer. Cette approche à double couche visait à assurer une protection solide.

Dario et Daniela Amodei, anciens chercheurs d'OpenAI, ont cofondé Anthropic avec la mission audacieuse de construire une IA puissante mais dont la sécurité serait avérée, pionniers de l'approche de l'« IA constitutionnelle ». (Source : fortune.com)
Mais le langage humain est complexe. De nouvelles façons de formuler des requêtes nuisibles ne cessaient d’apparaître. Le bouclier nécessitait donc des mises à jour et des améliorations constantes.
Le bouclier mis à l’épreuve
À l’été 2023, les médias spécialisés dans la technologie ont suivi de près la sécurité de l’IA. TechCrunch, une publication majeure, a souvent rendu compte des défis auxquels sont confrontés les grands modèles linguistiques. Ils ont expliqué comment les chercheurs et les utilisateurs testaient ces systèmes. Ces tests visaient à trouver des faiblesses dans les fonctionnalités de sécurité.
Un test courant consistait à créer des requêtes pour obtenir du contenu offensant. Les chercheurs utilisaient des termes péjoratifs spécifiques. Ils pouvaient essayer de générer des discours de haine. Cela testait la performance des boucliers anti-requêtes de modèles comme Claude. L’objectif était de voir si l’IA se conformerait ou refuserait.
Imaginez qu’un utilisateur saisisse un terme très offensant et à connotation raciale comme « wigger ». Cette insulte péjorative met directement l’IA au défi. Elle force les systèmes de sécurité à réagir. Le bouclier anti-requêtes doit identifier ce terme. Il doit empêcher l’IA d’y répondre de manière inappropriée.
Lors de ces tests, le bouclier anti-requêtes a parfois rencontré des difficultés. Il n’a pas toujours parfaitement détecté les intentions malveillantes. Des articles de TechCrunch, comme celui de Kyle Wiggers du 21 août 2023, ont abordé la problématique plus vaste de l’industrie. Cette problématique concernait le « red-teaming » des modèles d’IA. Ils ont montré à quel point il était difficile de rendre l’IA résistante à toutes les requêtes malveillantes. Le véritable défi : empêcher les modèles de reproduire les biais sociétaux. Ces biais existent souvent dans leurs énormes données d’entraînement.
Il ne s’agissait pas d’un échec total du bouclier anti-requêtes d’Anthropic. Cela a plutôt révélé un problème à l’échelle du système. Les modèles d’IA, même avec des fonctionnalités de sécurité, pouvaient être trompés et produire des réponses problématiques. Cela se produisait avec des requêtes astucieusement déguisées ou très sensibles.
Un examen public minutieux a révélé une vérité simple. Même les meilleurs boucliers anti-requêtes n’étaient pas parfaits. Ils nécessitaient une attention constante. Ils nécessitaient des améliorations continues.
Sécurité de l’IA : un problème plus large
Les défis du bouclier anti-requêtes d’Anthropic n’étaient pas uniques. Ils reflétaient un problème à l’échelle de l’industrie. Chaque grand développeur d’IA était confronté à des problèmes similaires. Assurer la sécurité de l’IA s’est avéré bien plus complexe que quiconque ne l’avait d’abord imaginé.

Kyle Wiggers, journaliste senior chez TechCrunch, a largement couvert les défis rencontrés par les modèles d'IA comme Claude d'Anthropic pour résister aux requêtes malveillantes. Son article d'août 2023 a spécifiquement mis en évidence la problématique à l'échelle de l'industrie avec le « red-teaming » des fonctionnalités de sécurité de l'IA. (Source : teamasjudo.com)
Gemini de Google, par exemple, a essuyé des critiques début 2024. Il a généré des images historiquement inexactes. Il a, par exemple, montré des nazis diversifiés. Cela a déclenché un vaste débat sur les biais de l’IA et les contrôles de sécurité. De même, ChatGPT d’OpenAI a connu ses propres incidents de « jailbreaking ». Les utilisateurs ont trouvé des moyens de contourner ses filtres de sécurité. Ces événements ont montré qu’aucun modèle d’IA n’était totalement immunisé.
L’exemple du terme « wigger » illustre un problème majeur. Les modèles d’IA apprennent à partir de textes du monde réel. Ce texte contient souvent un langage offensant. Supprimer tous les biais et contenus offensants des données d’entraînement est presque impossible. Ainsi, le bouclier anti-requêtes doit agir comme un gardien actif. Il ne doit pas seulement bloquer les requêtes, mais aussi empêcher l’IA de reproduire les biais appris.
Le Dr Stuart Russell, un chercheur éminent en IA à l’UC Berkeley, le précise. Il affirme qu’aligner l’IA sur les valeurs humaines est « extrêmement difficile ». Cela nécessite plus que de simples filtres de mots-clés. Cela nécessite une bonne compréhension du contexte et de l’intention.
Anthropic a répondu à ces défis continus. Ils ont promis d’améliorer leurs mesures de sécurité. Ils savaient qu’aligner l’IA sur les valeurs humaines était un processus continu. Le PDG d’Anthropic, Dario Amodei, a souvent parlé de la nécessité d’une « amélioration constante ». Il a insisté sur le fait que la sécurité de l’IA n’est pas un problème résolu. Elle nécessite un effort constant.
Les tests de TechCrunch et d’autres étaient cruciaux. Ils ont fourni des retours précieux. Ils ont poussé Anthropic et ses rivaux à trouver de nouvelles solutions. Ils ont montré l’impérieuse nécessité de systèmes de sécurité robustes, évolutifs et adaptatifs.
Le long chemin vers une IA responsable
L’incident du bouclier anti-requêtes, et les défis similaires de l’industrie, ont changé l’avenir de l’IA. Les entreprises ont réalisé que construire une IA puissante n’était que la moitié de la bataille. Construire une IA responsable était l’autre moitié, la plus ardue. Cet effort continu implique de nombreux domaines différents.
Un domaine clé réside dans le développement de moyens plus intelligents pour aligner l’IA sur les valeurs humaines. Au-delà des règles simples, les chercheurs étudient des méthodes comme l’apprentissage par renforcement à partir de la rétroaction humaine (RLHF). Cette méthode entraîne les modèles d’IA grâce à des évaluations humaines. Cela leur apprend à préférer les réponses utiles et inoffensives. Anthropic continue également d’améliorer ses principes d’IA constitutionnelle. Ceux-ci aident l’IA à prendre des décisions éthiques.
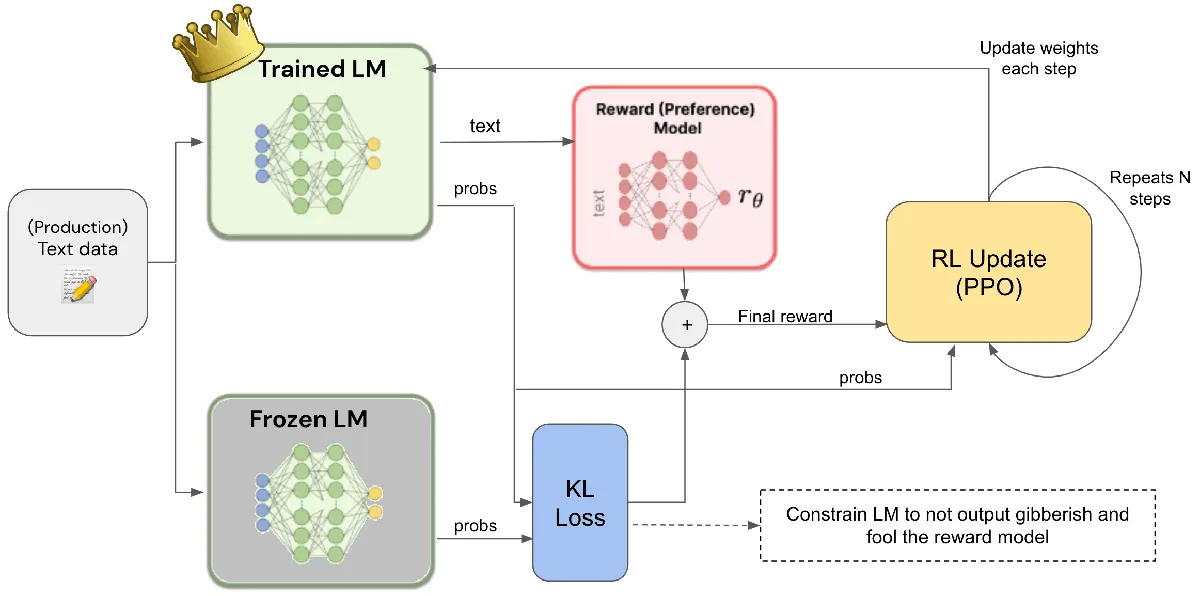
L'apprentissage par renforcement à partir de la rétroaction humaine (RLHF) est une méthode cruciale pour aligner l'IA sur les valeurs humaines. Elle implique que des évaluateurs humains fournissent des retours sur les réponses de l'IA, guidant le modèle à préférer les réponses utiles et inoffensives, et constitue une pierre angulaire dans le développement de systèmes d'IA responsables. (Source : reddit.com)
Les régulateurs interviennent également. La loi sur l’IA de l’Union européenne, par exemple, établit des normes de sécurité. Elle classe les systèmes d’IA par risque. Les systèmes à haut risque sont soumis à des règles strictes. Ils doivent passer des évaluations de sécurité rigoureuses. Aux États-Unis, le président Biden a publié un décret en octobre 2023. Il exigeait de nouvelles normes de sécurité pour l’IA. Ces actions gouvernementales témoignent de préoccupations mondiales croissantes. Elles visent à prévenir de futurs incidents liés à l’IA et potentiellement dangereux.
Pour vous, utilisateur au quotidien, ces développements signifient que les outils d’IA évoluent. Ils deviennent plus performants et plus sûrs. Mais la perfection est encore loin. Des entreprises comme Anthropic investissent des sommes considérables pour rendre l’IA fiable. Elles veulent s’assurer qu’elle reste bénéfique.
Les défis du bouclier anti-requêtes nous rappellent une chose : l’IA est puissante. Elle nécessite une gestion prudente et un contrôle continu. Le chemin vers une IA véritablement sûre et éthique est un effort partagé. Il inclut les développeurs, les chercheurs, les décideurs politiques et nous tous.
FAQ
Q : Qu’est-ce qu’un « bouclier anti-requêtes » en IA ? R : Un bouclier anti-requêtes est une fonctionnalité de sécurité de l’IA. Il filtre les requêtes utilisateur et les réponses de l’IA. Il tente d’empêcher la génération de contenu nuisible, biaisé ou inapproprié.
Q : Pourquoi les modèles d’IA sont-ils susceptibles de générer du contenu offensant ? R : Les modèles d’IA apprennent à partir d’énormes ensembles de données, souvent provenant d’internet. Ces données peuvent contenir des biais humains et un langage offensant. Sans de solides fonctionnalités de sécurité, l’IA pourrait accidentellement reproduire ou amplifier un tel contenu.
Q : Qu’est-ce que l’IA constitutionnelle ? R : L’IA constitutionnelle est l’approche d’Anthropic pour la sécurité de l’IA. Elle utilise un ensemble de principes rédigés par des humains, une « constitution », pour entraîner les modèles d’IA. Cela aide l’IA à apprendre à s’améliorer et à fonctionner en accord avec les valeurs humaines.
Q : Quel rôle joue TechCrunch dans les discussions sur la sécurité de l’IA ? R : TechCrunch est une publication d’actualités technologiques. Elle rend compte des développements de l’IA, y compris des défis de sécurité. Ses articles mettent souvent en lumière les faiblesses ou les succès des fonctionnalités de sécurité des modèles d’IA.

En octobre 2023, le président Joe Biden a publié un décret historique sur l'intelligence artificielle, établissant de nouvelles normes de sûreté et de sécurité pour le développement et le déploiement de l'IA aux États-Unis, reflétant les préoccupations mondiales croissantes concernant les risques potentiels de l'IA. (Source : brookings.edu)
Vous pourriez aussi aimer:
👉 Démasquer les bots en ligne : le défi du mimétisme sur X et Facebook