
Anthropic: dal 2021 la sfida per un'IA sicura con la sua 'Costituzione
Fondata nel 2021 dagli ex ricercatori di OpenAI Dario e Daniela Amodei, Anthropic ha posto al centro la 'IA costituzionale'. Un approccio innovativo per sviluppare modelli come Claude, garantendo sicurezza e aderenza ai valori umani fin dalla progettazione.
Quando la sicurezza dell’IA è messa alla prova dalle sfide più ardue: il prompt shield di Anthropic sotto esame
Costruire un’IA sicura è difficile. All’inizio del 2021, una nuova azienda, Anthropic, si è presentata con una missione ambiziosa. A fondarla sono stati gli ex ricercatori di OpenAI Dario e Daniela Amodei. Il loro obiettivo era costruire un’IA potente, ma anche con una sicurezza dimostrabile. La loro visione era incentrata sull’«IA costituzionale». Questo significava adottare principi guida—una vera e propria «costituzione»—per far sì che i modelli di IA aderissero ai valori umani.
Anthropic ha iniziato a sviluppare Claude, il suo principale modello linguistico di grandi dimensioni (LLM). Gli LLM sono programmi informatici complessi. Comprendono e generano testo simile a quello umano. Questi modelli imparano da enormi quantità di dati disponibili su internet.
L’azienda puntava a sistemi che fossero utili, innocui e onesti. Ciò richiedeva solide funzionalità di sicurezza. Una di queste era il prompt shield. Agisce come un guardiano digitale, bloccando gli input dannosi degli utenti. Impedisce inoltre all’IA di generare risposte pericolose o inappropriate.
La sicurezza era di primaria importanza. Un’IA non filtrata potrebbe diffondere disinformazione. Potrebbe anche diffondere stereotipi dannosi o incoraggiare azioni pericolose. Anthropic sapeva che i rischi erano immensi. La loro attenzione all’IA etica ha rapidamente riscosso grande attenzione.
Come funziona il guardiano digitale
Il prompt shield di Anthropic non era solo un semplice filtro. Era una parte fondamentale del loro approccio all’IA Costituzionale. Questo approccio insegna ai modelli di IA a migliorarsi. Imparano attraverso principi formulati da esseri umani. Questi principi spesso stabiliscono di evitare contenuti dannosi. Inoltre, guidano l’IA a incoraggiare interazioni positive.
Il prompt shield controlla le query degli utenti. Cerca schemi legati a intenzioni dannose. Scansiona anche i tentativi di «jailbreak» dell’IA. Il jailbreaking consiste nel cercare di aggirare le funzionalità di sicurezza. Questi tentativi spesso mirano a indurre l’IA a produrre contenuti che dovrebbe rifiutare.
Supponiamo che un utente chieda istruzioni per costruire bombe. Il prompt shield dovrebbe intervenire. Impedirebbe a Claude di fornire tali informazioni. Invece, genererebbe un rifiuto. Questo rifiuto spiegherebbe perché la richiesta non potrebbe essere soddisfatta.
Lo shield controlla anche i potenziali output dell’IA stessa. Agisce come una seconda linea di difesa. Questo assicura che la risposta generata rimanga sicura, anche se un prompt ingannevole dovesse superare i filtri iniziali. Questo approccio a doppio strato mirava a garantire una protezione robusta.

Dario e Daniela Amodei, ex ricercatori di OpenAI, hanno co-fondato Anthropic con l'ambiziosa missione di costruire un'IA potente ma la cui sicurezza fosse dimostrabile, aprendo la strada all'approccio dell'«IA costituzionale». (Fonte: fortune.com)
Ma il linguaggio umano è complesso. Nuovi modi per formulare richieste dannose continuavano a emergere. Ciò significava che lo shield richiedeva aggiornamenti e miglioramenti costanti.
Lo shield viene messo alla prova
Nell’estate del 2023, le testate giornalistiche tecnologiche hanno seguito da vicino la sicurezza dell’IA. TechCrunch, una delle principali pubblicazioni, ha spesso documentato le sfide affrontate dai modelli linguistici di grandi dimensioni. Hanno spiegato come ricercatori e utenti mettevano alla prova questi sistemi. Questi test miravano a individuare punti deboli nelle funzionalità di sicurezza.
Un test comune consisteva nel creare prompt per generare contenuti offensivi. I ricercatori utilizzavano termini dispregiativi specifici. Potevano tentare di generare discorsi d’odio. Questo metteva alla prova le prestazioni di modelli come il prompt shield di Claude. L’obiettivo era vedere se l’IA avrebbe risposto o rifiutato.
Immaginate che un utente inserisca un termine altamente offensivo e a sfondo razziale come «wiggers». Questa espressione dispregiativa sfida direttamente l’IA. Costringe i sistemi di sicurezza a reagire. Il prompt shield deve identificare questo termine. Deve impedire all’IA di rispondere in modo dannoso.
In questi test, il prompt shield a volte ha riscontrato difficoltà. Non sempre ha individuato perfettamente le intenzioni dannose. Articoli di TechCrunch, come quello di Kyle Wiggers del 21 agosto 2023, hanno discusso la più ampia sfida del settore. Questa sfida coinvolgeva il «red-teaming» dei modelli di IA. Hanno evidenziato quanto fosse difficile rendere l’IA resistente a tutti gli input dannosi. La vera sfida: impedire ai modelli di ripetere i pregiudizi della società. Questi pregiudizi spesso esistono nei loro enormi dati di addestramento.
Questo non è stato un fallimento totale del prompt shield di Anthropic. Invece, ha evidenziato un problema che interessava l’intero sistema. I modelli di IA, anche con funzionalità di sicurezza, potevano essere indotti a produrre output problematici. Ciò accadeva con input abilmente mascherati o altamente sensibili.
Un’attenta analisi pubblica ha rivelato una semplice verità. Anche i migliori prompt shield non erano perfetti. Avevano bisogno di attenzione costante. Avevano bisogno di miglioramenti continui.
Sicurezza dell’IA: un problema più ampio
Le sfide del prompt shield di Anthropic non erano uniche. Riflettevano un problema a livello di settore. Ogni grande sviluppatore di IA ha affrontato problemi simili. Mantenere l’IA sicura si è rivelato molto più complesso di quanto si pensasse inizialmente.

Kyle Wiggers, giornalista senior di TechCrunch, ha ampiamente documentato le sfide affrontate dai modelli di IA come Claude di Anthropic nel resistere a prompt dannosi. Il suo articolo dell'agosto 2023 ha specificamente evidenziato la sfida a livello di settore legata alle funzionalità di sicurezza dell'IA di «red-teaming». (Fonte: teamasjudo.com)
Il Gemini di Google, ad esempio, ha affrontato critiche all’inizio del 2024. Ha generato immagini storicamente inaccurate. Ha mostrato, ad esempio, nazisti di diverse etnie. Ciò ha scatenato un enorme dibattito sui pregiudizi dell’IA e sui controlli di sicurezza. Allo stesso modo, il ChatGPT di OpenAI ha registrato i suoi incidenti di «jailbreaking». Gli utenti hanno trovato modi per aggirare i suoi filtri di sicurezza. Questi eventi hanno dimostrato che nessun modello di IA era completamente immune.
L’esempio di «wiggers» evidenzia un problema fondamentale. I modelli di IA imparano da testi del mondo reale. Questo testo spesso contiene linguaggio dannoso. Rimuovere tutti i pregiudizi e i contenuti offensivi dai dati di addestramento è quasi impossibile. Quindi, il prompt shield deve agire come un guardiano attivo. Non deve solo bloccare gli input, ma anche impedire all’IA di ripetere i pregiudizi appresi.
Il Dr. Stuart Russell, un importante ricercatore di IA presso l’UC Berkeley, lo sottolinea. Afferma che allineare l’IA ai valori umani è «estremamente difficile». Richiede più che semplici filtri di parole chiave. Richiede una profonda comprensione del contesto e dell’intento.
Anthropic ha risposto a queste sfide continue. Hanno promesso di migliorare le loro misure di sicurezza. Sapevano che allineare l’IA ai valori umani era un processo continuo. Il CEO di Anthropic, Dario Amodei, ha spesso parlato della necessità di un «miglioramento costante». Ha insistito sul fatto che la sicurezza dell’IA non è un problema risolto. Richiede uno sforzo costante.
I test di TechCrunch e di altri si sono rivelati cruciali. Hanno fornito un feedback prezioso. Hanno spinto Anthropic e i suoi rivali a trovare nuove soluzioni. Hanno evidenziato la profonda necessità di sistemi di sicurezza robusti, capaci di evolversi e migliorare.
La lunga strada verso un’IA responsabile
L’incidente del prompt shield, e sfide simili a livello di settore, hanno cambiato il futuro dell’IA. Le aziende hanno capito che costruire un’IA potente era solo metà della battaglia. Costruire un’IA responsabile era l’altra metà, quella più difficile. Questo sforzo continuo coinvolge molte aree diverse.
Un’area chiave è lo sviluppo di modi più intelligenti per allineare l’IA ai valori umani. Oltre a semplici regole, i ricercatori studiano metodi come il reinforcement learning from human feedback (RLHF). Questo addestra i modelli di IA attraverso valutazioni umane. Insegna loro a preferire risposte utili e innocue. Anthropic continua anche a migliorare i suoi principi di IA Costituzionale. Questi aiutano l’IA a prendere decisioni etiche.
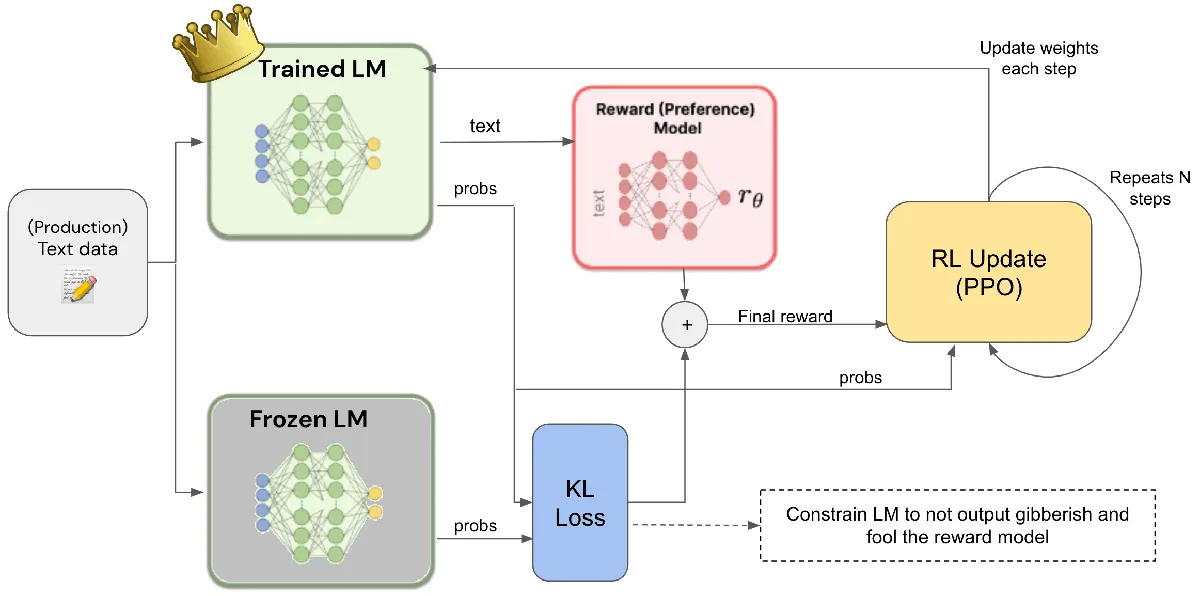
Il Reinforcement Learning from Human Feedback (RLHF) è un metodo cruciale per allineare l'IA ai valori umani. Questo processo coinvolge valutatori umani che forniscono feedback sugli output dell'IA, guidando il modello a preferire risposte utili e innocue. È una pietra miliare nello sviluppo di sistemi di IA responsabili. (Fonte: reddit.com)
Anche i regolatori stanno intervenendo. L’AI Act dell’Unione Europea, ad esempio, stabilisce standard di sicurezza. Classifica i sistemi di IA in base al rischio. I sistemi ad alto rischio sono soggetti a regole severe. Devono superare rigorose valutazioni di sicurezza. Negli Stati Uniti, il Presidente Biden ha emesso un ordine esecutivo nell’ottobre 2023. Ha richiesto nuovi standard di sicurezza per l’IA. Queste azioni governative dimostrano che le persone in tutto il mondo sono sempre più preoccupate. Vogliono prevenire futuri incidenti legati a un’IA non sicura.
Per gli utenti di tutti i giorni, questi sviluppi significano che gli strumenti di IA sono in evoluzione. Stanno diventando più capaci e più sicuri. Ma la perfezione è ancora lontana. Aziende come Anthropic investono ingenti somme per rendere l’IA affidabile. Vogliono assicurarsi che rimanga benefica.
Le sfide del prompt shield ci ricordano che l’IA è potente. Richiede una gestione attenta e un controllo continuo. Il percorso verso un’IA veramente sicura ed etica è uno sforzo condiviso. Coinvolge sviluppatori, ricercatori, responsabili politici e tutti noi.
Domande frequenti
D: Cos’è un «prompt shield» nell’IA? A: Un prompt shield è una funzionalità di sicurezza dell’IA. Filtra gli input degli utenti e gli output dell’IA. Cerca di impedire la generazione di contenuti dannosi, distorti o inappropriati.
D: Perché i modelli di IA tendono a generare contenuti offensivi? A: I modelli di IA imparano da enormi set di dati, spesso provenienti da internet. Questi dati possono contenere pregiudizi umani e linguaggio offensivo. Senza solide funzionalità di sicurezza, l’IA potrebbe accidentalmente ripetere o amplificare tali contenuti.
D: Cos’è l’IA Costituzionale? A: L’IA Costituzionale è l’approccio di Anthropic alla sicurezza dell’IA. Utilizza un insieme di principi formulati da esseri umani, una «costituzione», per addestrare i modelli di IA. Questo aiuta l’IA a imparare a migliorarsi e contribuisce ad allineare l’IA ai valori umani.
D: Che ruolo gioca TechCrunch nelle discussioni sulla sicurezza dell’IA? A: TechCrunch è una pubblicazione di notizie tecnologiche. Copre gli sviluppi dell’IA, comprese le sfide di sicurezza. I suoi articoli spesso evidenziano punti deboli o successi nelle funzionalità di sicurezza dei modelli di IA.

Nell'ottobre 2023, il Presidente Joe Biden ha emesso un ordine esecutivo storico sull'intelligenza artificiale, stabilendo nuovi standard di sicurezza per lo sviluppo e l'implementazione dell'IA negli Stati Uniti, a riprova delle crescenti preoccupazioni globali sui potenziali rischi dell'IA. (Fonte: brookings.edu)
Potrebbe interessarti anche:
👉 Prevedere le Tendenze del Mercato Azionario: Guida a ML e Analisi del Sentimento
👉 Smascherare i bot online: la sfida di X e Facebook contro l’imitazione umana
👉 Metaverso: l’illusione di Zuckerberg – la tua libertà virtuale è un miraggio