
Anthropic: la IA constitucional, ¿la apuesta definitiva por la seguridad?
Fundada en 2021 por exinvestigadores de OpenAI, Anthropic se propuso construir una IA potente y segura. Su enfoque pionero se basa en la "IA constitucional", utilizando principios rectores para alinear los modelos con valores humanos.
Cuando la seguridad de la IA se enfrenta a sus pruebas más difíciles: el ‘prompt shield’ de Anthropic a examen
Construir una IA segura es difícil. A principios de 2021, nació una nueva empresa, Anthropic, con una misión audaz. Fue fundada por los exinvestigadores de OpenAI Dario y Daniela Amodei, quienes buscaban desarrollar una IA potente, pero cuya seguridad pudiera demostrarse. Su visión se centró en la “IA constitucional”, lo que implicaba emplear principios rectores —una “constitución”— para que los modelos de IA se adhirieran a los valores humanos.
Anthropic comenzó a desarrollar Claude, su principal modelo de lenguaje grande (LLM). Los LLM son programas informáticos complejos. Entienden y generan texto similar al humano. Estos modelos aprenden de grandes cantidades de datos de internet.
La empresa buscaba sistemas útiles, inofensivos y honestos. Esto requería sólidas características de seguridad. Una de ellas era el prompt shield, que actúa como un guardián digital, bloqueando las entradas de usuario dañinas y evitando que la IA genere respuestas peligrosas o inapropiadas.
La seguridad era primordial. Una IA sin filtrar podría difundir desinformación, propagar estereotipos dañinos o fomentar acciones peligrosas. Anthropic sabía que los riesgos eran inmensos. Su enfoque en la IA ética atrajo rápidamente la atención y un minucioso escrutinio.
Cómo funciona el guardián digital
El prompt shield de Anthropic no era un simple filtro. Era una parte central de su enfoque de IA Constitucional. Este enfoque enseña a los modelos de IA a perfeccionarse, aprendiendo a partir de principios escritos por humanos. Estos principios suelen establecer la necesidad de evitar contenido dañino y de fomentar interacciones positivas.
El prompt shield analiza las consultas de los usuarios, buscando patrones asociados a intenciones dañinas. También detecta intentos de “jailbreak” en la IA. El “jailbreaking” consiste en intentar eludir las características de seguridad, a menudo con el objetivo de que la IA produzca contenido que está diseñada para rechazar.
Digamos que un usuario pide instrucciones para construir una bomba. El prompt shield debería intervenir, impidiendo que Claude proporcione esa información. En su lugar, generaría una negativa que explicaría por qué la solicitud no podía ser satisfecha.
El escudo también supervisa las respuestas potenciales de la propia IA. Actúa como una segunda línea de defensa, asegurando que una respuesta generada se mantenga segura, incluso si un prompt engañoso logra pasar. Este enfoque de doble capa pretendía ofrecer una protección sólida.

Dario y Daniela Amodei, exinvestigadores de OpenAI, cofundaron Anthropic con la audaz misión de construir una IA potente, pero cuya seguridad pudiera demostrarse, siendo pioneros en el enfoque de la 'IA constitucional'. (Fuente: fortune.com)
Pero el lenguaje humano es complejo. Continuaban surgiendo nuevas formas de expresar solicitudes dañinas, lo que implicaba que el escudo necesitaba actualizaciones y mejoras constantes.
El escudo se pone a prueba
En el verano de 2023, los medios de noticias tecnológicas siguieron de cerca la seguridad de la IA. TechCrunch, una publicación destacada, informaba a menudo sobre los desafíos que enfrentaban los modelos de lenguaje grandes. Explicaban cómo investigadores y usuarios ponían a prueba estos sistemas, buscando identificar debilidades en sus características de seguridad.
Una prueba común consistía en crear prompts para generar contenido ofensivo. Los investigadores empleaban términos despectivos específicos, llegando a intentar generar discurso de odio. Esto ponía a prueba la eficacia del prompt shield en modelos como Claude, con el objetivo de determinar si la IA accedía o se negaba.
Imagina que un usuario introduce un término sumamente ofensivo y de connotación racial como “wiggers”. Este insulto despectivo supone un desafío directo para la IA, lo que obliga a los sistemas de seguridad a reaccionar. El prompt shield debe identificar este término y evitar que la IA responda de forma dañina.
En estas pruebas, el prompt shield a veces mostró dificultades. No siempre detectó con precisión las intenciones dañinas. Artículos de TechCrunch, como uno de Kyle Wiggers del 21 de agosto de 2023, abordaron la lucha más amplia de la industria, que incluía el “red-teaming” de los modelos de IA. Mostraron la dificultad de hacer que la IA fuera resistente a todas las entradas maliciosas. El verdadero desafío residía en evitar que los modelos repitieran los sesgos sociales, que suelen estar presentes en sus enormes datos de entrenamiento.
Esto no fue un fracaso total del prompt shield de Anthropic. Más bien, evidenció un problema sistémico: los modelos de IA, incluso con características de seguridad, podían ser inducidos a generar resultados problemáticos. Esto ocurría con entradas hábilmente disfrazadas o de alta sensibilidad.
Un minucioso examen público reveló una verdad sencilla: incluso los mejores prompt shields no eran perfectos y necesitaban atención y mejoras continuas.
La seguridad de la IA: un problema más amplio
Los desafíos del prompt shield de Anthropic no eran únicos, sino que reflejaban un problema que afectaba a toda la industria. Todos los grandes desarrolladores de IA se enfrentaban a problemas similares, y mantener la IA segura resultó ser mucho más complejo de lo que se había imaginado inicialmente.

Kyle Wiggers, reportero sénior de TechCrunch, cubrió en profundidad los desafíos a los que se enfrentan los modelos de IA como Claude de Anthropic para resistir prompts dañinos. Su artículo de agosto de 2023 destacó específicamente el desafío que supone el 'red-teaming' para las características de seguridad de la IA en toda la industria. (Fuente: teamasjudo.com)
Gemini de Google, por ejemplo, enfrentó críticas a principios de 2024 al generar imágenes históricamente inexactas, como nazis diversos. Esto desató un intenso debate sobre el sesgo de la IA y los controles de seguridad. Del mismo modo, ChatGPT de OpenAI experimentó sus propios incidentes de “jailbreaking”, donde los usuarios descubrieron formas de eludir sus filtros de seguridad. Estos eventos demostraron que ningún modelo de IA es totalmente inmune.
El ejemplo de “wiggers” ilustra un problema fundamental: los modelos de IA aprenden del texto del mundo real, que suele contener lenguaje dañino. Resulta casi imposible eliminar todo el sesgo y el contenido ofensivo de los datos de entrenamiento. Por lo tanto, el prompt shield debe funcionar como un guardián activo, no solo bloqueando las entradas, sino también evitando que la IA repita los sesgos aprendidos.
El Dr. Stuart Russell, un importante investigador de IA en UC Berkeley, lo subraya. Afirma que alinear la IA con los valores humanos es “extremadamente difícil”, ya que requiere más que simples filtros de palabras clave; exige una profunda comprensión del contexto y la intención.
Anthropic reaccionó ante estos desafíos constantes, comprometiéndose a mejorar sus medidas de seguridad. Eran conscientes de que alinear la IA con los valores humanos era un proceso continuo. De hecho, el CEO de Anthropic, Dario Amodei, solía hablar de la necesidad de una “mejora constante” e insistía en que la seguridad de la IA no es un problema resuelto, sino que requiere un esfuerzo constante.
Las pruebas de TechCrunch y otros resultaron cruciales. Ofrecieron una retroalimentación valiosa que impulsó a Anthropic y a sus rivales a buscar nuevas soluciones. Evidenciaron la profunda necesidad de sistemas de seguridad robustos, capaces de adaptarse y mejorar.
El largo camino hacia una IA responsable
El incidente del prompt shield, junto con desafíos similares de la industria, redefinieron el futuro de la IA. Las empresas se dieron cuenta de que construir una IA potente era solo la mitad de la batalla; la otra mitad, la más difícil, era construir una IA responsable. Este esfuerzo continuo abarca diversas áreas.
Un área clave es el desarrollo de formas más inteligentes de alinear la IA con los valores humanos. Más allá de las reglas sencillas, los investigadores exploran métodos como el aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF). Estos métodos entrenan modelos de IA mediante evaluaciones humanas, enseñándoles a preferir respuestas útiles e inofensivas. Anthropic también continúa mejorando sus principios de IA Constitucional, que guían a la IA en la toma de decisiones éticas.
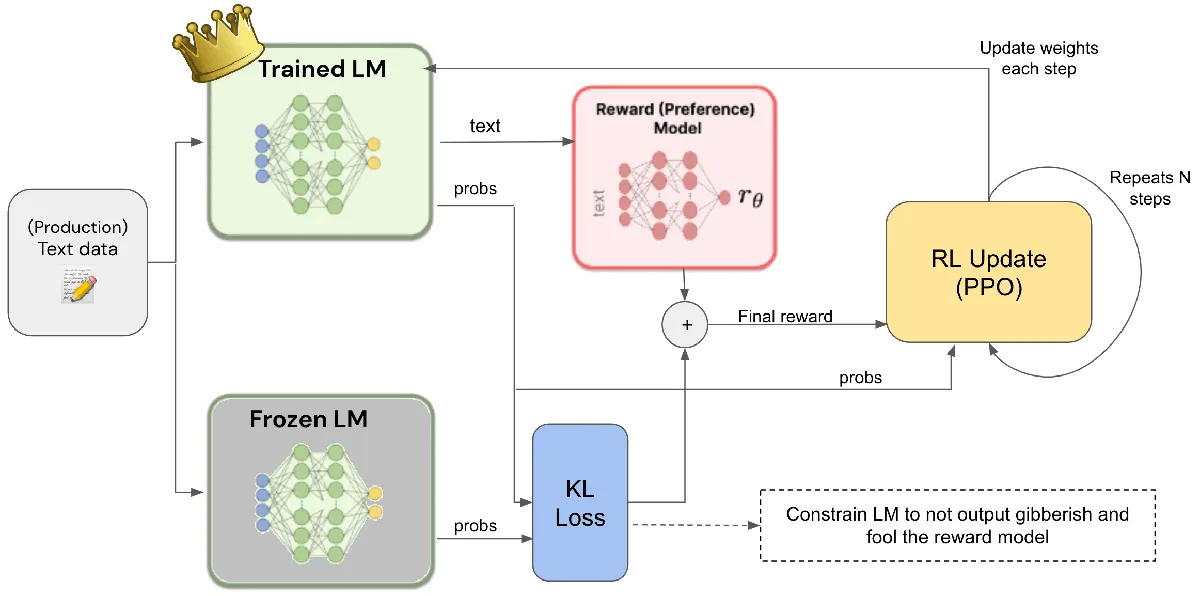
El aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF) es un método crucial para alinear la IA con los valores humanos. Implica que evaluadores humanos proporcionen retroalimentación sobre las salidas de la IA, guiando al modelo a preferir respuestas útiles e inofensivas. Es, además, una piedra angular en el desarrollo de sistemas de IA responsables. (Fuente: reddit.com)
Los reguladores también están tomando medidas. La Ley de IA de la Unión Europea, por ejemplo, establece estándares de seguridad y clasifica los sistemas de IA según su riesgo. Los sistemas de alto riesgo están sujetos a reglas estrictas y deben pasar evaluaciones de seguridad rigurosas. En EE. UU., el presidente Biden emitió una orden ejecutiva en octubre de 2023, que exigía nuevos estándares de seguridad para la IA. Estas acciones gubernamentales demuestran una creciente preocupación global por detener futuros incidentes de IA insegura.
Para el usuario cotidiano, estos desarrollos implican que las herramientas de IA están evolucionando, volviéndose más capaces y seguras. Pero la perfección aún está lejos. Empresas como Anthropic invierten grandes sumas para que la IA sea confiable y buscan asegurar que siga siendo beneficiosa.
Los desafíos del prompt shield nos recuerdan que la IA es poderosa y requiere una gestión cuidadosa y una supervisión continua. El camino hacia una IA verdaderamente segura y ética es un esfuerzo compartido que involucra a desarrolladores, investigadores, formuladores de políticas y a todos nosotros.
Preguntas frecuentes
P: ¿Qué es un “prompt shield” en IA? R: Un prompt shield es una característica de seguridad de la IA que filtra las entradas del usuario y las salidas de la IA, intentando detener la generación de contenido dañino, sesgado o inapropiado.
P: ¿Por qué los modelos de IA tienden a generar contenido ofensivo? R: Los modelos de IA aprenden de enormes conjuntos de datos, a menudo de internet. Estos datos pueden contener sesgos humanos y lenguaje ofensivo. Sin características de seguridad sólidas, la IA podría repetir o exacerbar dicho contenido de forma accidental.
P: ¿Qué es la IA Constitucional? R: La IA Constitucional es el enfoque de Anthropic para la seguridad de la IA. Utiliza un conjunto de principios escritos por humanos, una “constitución”, para entrenar modelos de IA. Esto ayuda a la IA a perfeccionarse y a alinearse con los valores humanos.
P: ¿Qué papel juega TechCrunch en las discusiones sobre seguridad de la IA? R: TechCrunch es una publicación de noticias tecnológicas que informa sobre los desarrollos de la IA, incluidos sus desafíos de seguridad. Sus artículos suelen evidenciar las debilidades o los éxitos en las características de seguridad de los modelos de IA.

En octubre de 2023, el presidente Joe Biden emitió una orden ejecutiva histórica sobre inteligencia artificial, estableciendo nuevos estándares de seguridad para el desarrollo y despliegue de la IA en los Estados Unidos. Esta medida refleja las crecientes preocupaciones globales sobre los riesgos potenciales de la IA. (Fuente: brookings.edu)
También te puede interesar:
👉 Bots en línea: El reto de detectar su suplantación en X y Facebook