
Anthropic's 2021 AI Safety Bet: Can Prompt Shield Work?
Former OpenAI researchers Dario and Daniela Amodei founded Anthropic in early 2021 to build demonstrably safe AI using constitutional principles.
When AI Safety Faces Its Toughest Tests: Anthropic’s Prompt Shield Being Tested
Building safe AI is hard. In early 2021, a new company, Anthropic, emerged with a bold mission. Former OpenAI researchers Dario and Daniela Amodei founded it. They wanted to build AI that was powerful, but also demonstrably safe. Their vision centered on “constitutional AI.” This meant using guiding principles—a “constitution”—to make AI models follow human values.
Anthropic began developing Claude, its main large language model (LLM). LLMs are complex computer programs. They understand and generate human-like text. These models learn from large amounts of internet data.
The company aimed for systems that were helpful, harmless, and honest. This needed strong safety features. One was the prompt shield. It acts as a digital guardian, blocking harmful user inputs. It also stops the AI from generating dangerous or inappropriate responses.
Safety was most important. Unfiltered AI could spread misinformation. It could also spread harmful stereotypes or encourage dangerous actions. Anthropic knew the risks were immense. Their focus on ethical AI quickly drew attention and close attention.
How the digital guardian works
Anthropic’s prompt shield wasn’t just a simple filter. It was a core part of their Constitutional AI approach. This approach teaches AI models to improve themselves. They learn based on human-written principles. These principles often say to avoid harmful content. They also tell the AI to encourage good interactions.
The prompt shield checks user queries. It looks for patterns linked to harmful intent. It also scans for attempts to “jailbreak” the AI. Jailbreaking means trying to get around safety features. These attempts often aim to make the AI produce content it’s designed to refuse.
Say a user asks for bomb-building instructions. The prompt shield should step in. It would stop Claude from giving that information. Instead, it would generate a refusal. This refusal would explain why the request couldn’t be fulfilled.
The shield also checks the AI’s own potential outputs. It acts as a second defense line. This makes sure a generated response stays safe, even if a tricky prompt gets through. This dual-layer approach aimed for strong protection.

Dario and Daniela Amodei, former OpenAI researchers, co-founded Anthropic with a bold mission to build powerful yet demonstrably safe AI, pioneering the 'constitutional AI' approach. (Source: fortune.com)
But human language is complex. New ways to phrase harmful requests kept appearing. This meant the shield needed constant updates and improvements.
The shield gets tested
In summer 2023, tech news outlets watched AI safety closely. TechCrunch, a major publication, often reported on the challenges facing large language models. They explained how researchers and users tested these systems. These tests tried to find weaknesses in safety features.
One common test involved creating prompts to get offensive content. Researchers used specific derogatory terms. They might try to generate hateful speech. This tested how well models like Claude’s prompt shield performed. The goal was to see if the AI would comply or refuse.
Imagine a user enters a highly offensive, racially charged term like “wiggers.” This derogatory slur directly challenges the AI. It forces the safety systems to react. The prompt shield must identify this term. It needs to stop the AI from responding to it in a harmful way.
In these tests, the prompt shield sometimes struggled. It didn’t always perfectly spot harmful intentions. TechCrunch articles, such as one by Kyle Wiggers on August 21, 2023, discussed the industry’s wider struggle. This struggle involved “red-teaming” AI models. They showed how hard it was to make AI resistant to all bad inputs. The real challenge: stopping models from repeating societal biases. These biases often exist in their huge training data.
This wasn’t a total failure of Anthropic’s prompt shield. Instead, it showed a problem across the whole system. AI models, even with safety features, could be tricked into problematic outputs. This happened with cleverly disguised or highly sensitive inputs.
Public close examination revealed a simple truth. Even the best prompt shields weren’t perfect. They needed constant attention. They needed ongoing improvements.
AI safety: a wider problem
Anthropic’s prompt shield challenges weren’t unique. They reflected an industry-wide problem. Every major AI developer struggled with similar issues. Keeping AI safe proved far more complex than anyone first thought.

Kyle Wiggers, a senior reporter at TechCrunch, extensively covered the challenges faced by AI models like Anthropic's Claude in resisting harmful prompts. His August 2023 article specifically highlighted the industry-wide struggle with 'red-teaming' AI safety features. (Source: teamasjudo.com)
Google’s Gemini, for example, faced criticism in early 2024. It generated historically inaccurate images. It showed diverse Nazis, for instance. This started a huge debate about AI bias and safety controls. Likewise, OpenAI’s ChatGPT had its own “jailbreaking” incidents. Users found ways to get around its safety filters. These events showed no AI model was fully immune.
The “wiggers” example shows a main problem. AI models learn from real-world text. This text often contains harmful language. Removing all bias and offensive content from training data is almost impossible. So, the prompt shield must act as an active guardian. It must not just block inputs, but also stop the AI from repeating learned biases.
Dr. Stuart Russell, an important AI researcher at UC Berkeley, makes this clear. He says making AI work in line with human values is “extremely difficult.” It needs more than keyword filters. It needs a good understanding of context and intent.
Anthropic responded to these ongoing challenges. They promised to improve their safety measures. They knew making AI work in line with human values was an ongoing process. Anthropic’s CEO, Dario Amodei, often spoke about needing “constant improvement.” He insisted AI safety isn’t a solved problem. It needs constant effort.
The testing from TechCrunch and others was very important. It gave valuable feedback. It pushed Anthropic and its rivals to find new solutions. It showed the deep need for strong, safety systems that can change and improve.
The long road to responsible AI
The prompt shield incident, and similar industry challenges, changed AI’s future. Companies realized building powerful AI was only half the battle. Building responsible AI was the other, harder half. This ongoing effort involves many different areas.
One key area is developing smarter ways to make AI work in line with human values. Beyond simple rules, researchers look into methods like reinforcement learning from human feedback (RLHF). This trains AI models through human evaluations. It teaches them to prefer helpful, harmless responses. Anthropic also keeps improving its Constitutional AI principles. These help the AI in making ethical decisions.
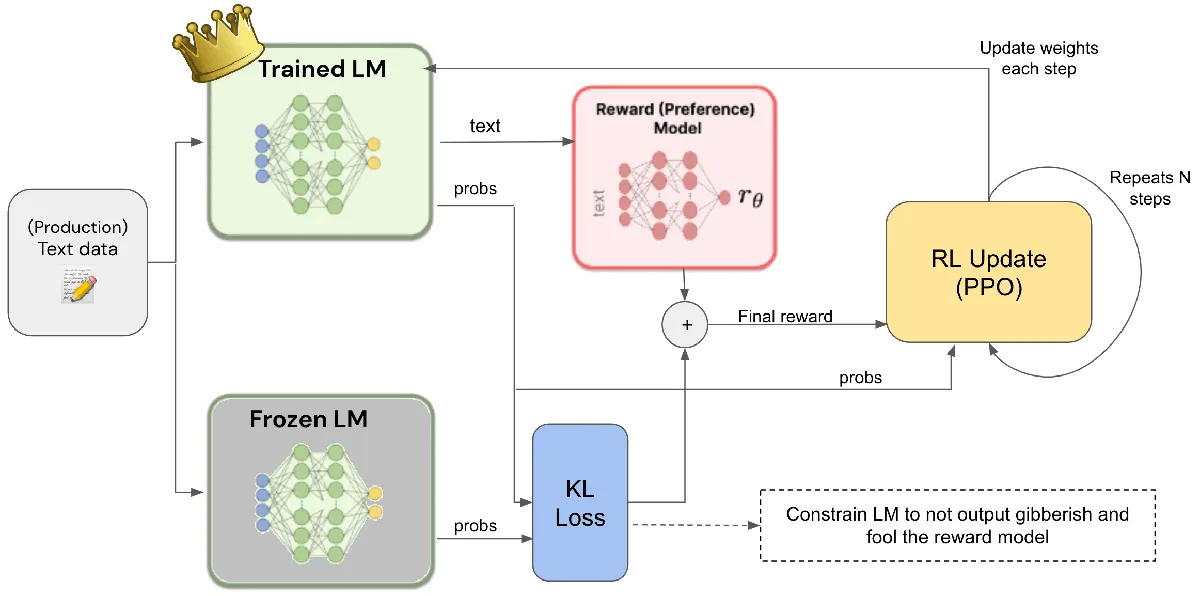
Reinforcement Learning from Human Feedback (RLHF) is a crucial method for aligning AI with human values. It involves human evaluators providing feedback on AI outputs, guiding the model to prefer helpful and harmless responses, and is a cornerstone in the development of responsible AI systems. (Source: reddit.com)
Regulators are stepping in too. The European Union’s AI Act, for example, sets safety standards. It groups AI systems by risk. High-risk systems face strict rules. They must pass tough safety assessments. In the US, President Biden issued an executive order in October 2023. It required new AI safety and security standards. These government actions show that people around the world are more worried. They want to stop future unsafe AI incidents.
For you, the everyday user, these developments mean AI tools are changing. They’re becoming more capable and safer. But perfection is still far off. Companies like Anthropic spend a lot of money in making AI reliable. They want to make sure it stays beneficial.
The prompt shield challenges remind us: AI is powerful. It needs careful management and ongoing checking. The journey to truly safe, ethical AI is a shared effort. It includes developers, researchers, policymakers, and all of us.
FAQ
Q: What is a “prompt shield” in AI? A: A prompt shield is an AI safety feature. It filters user inputs and AI outputs. It tries to stop the generation of harmful, biased, or inappropriate content.
Q: Why are AI models likely to generate offensive content? A: AI models learn from huge datasets, often from the internet. This data can contain human biases and offensive language. Without strong safety features, AI might accidentally repeat or make worse such content.
Q: What is Constitutional AI? A: Constitutional AI is Anthropic’s way to approach AI safety. It uses a set of human-written principles, a “constitution,” to train AI models. This helps the AI learn to improve itself. It makes the AI work in line with human values.
Q: What role does TechCrunch play in AI safety discussions? A: TechCrunch is a technology news publication. It reports on AI developments, including safety challenges. Its articles often shows weaknesses or successes in AI models’ safety features.

In October 2023, President Joe Biden issued a landmark executive order on artificial intelligence, establishing new safety and security standards for AI development and deployment in the United States, reflecting growing global concerns about AI's potential risks. (Source: brookings.edu)
You might also like:
👉 Predicting Stock Market Trends: ML & Sentiment Analysis Guide