
Así nacieron los deepfakes: el post de Reddit de 2017
Descubre cómo una publicación en Reddit en 2017, con videos de celebridades manipuladas, dio origen a los deepfakes. Esta innovadora tecnología de IA desató un debate mundial y redefinió la percepción de la realidad.
Deepfakes: El falsificador y el detective
En diciembre de 2017, un usuario de Reddit llamado “deepfakes” publicó videos inquietantes. Estos videos sustituían los rostros de celebridades por los de actrices de cine para adultos. El efecto fue impactante y parecía real para su época. Esto marcó el debut público de los medios sintéticos. Desató un debate global sobre los videos manipulados.
Estas creaciones, pronto llamadas deepfakes, representaron un avance significativo en la inteligencia artificial. Difuminaron la línea entre la realidad genuina y la fabricada. La tecnología subyacente no era del todo nueva. Se basaba en décadas de investigación en aprendizaje automático. Sin embargo, su disponibilidad generalizada y su alta calidad visual eran novedosas.
En pocas palabras, un deepfake utiliza IA para crear imágenes, audio o video realistas. Sustituye la imagen de una persona por la de otra. Esto a menudo implica intercambiar rostros o alterar el habla. El objetivo es hacer que el contenido falso parezca auténtico. Esta tecnología es ahora común. Influye en todo, desde el entretenimiento hasta las campañas de desinformación.
Primeros días: autoencoders y los primeros intercambios
Los conceptos iniciales de los deepfakes comenzaron mucho antes. Los investigadores exploraron cómo las máquinas podían aprender de los datos. Un desarrollo clave tuvo lugar en 2006. El profesor Geoffrey Hinton y su equipo en la Universidad de Toronto introdujeron el aprendizaje profundo. Este método utilizaba redes neuronales con muchas capas. Permitía a las computadoras procesar patrones complejos.
Este trabajo inicial condujo a una herramienta central de los deepfakes: el autoencoder. Un autoencoder es un tipo de red neuronal. Aprende a comprimir datos y luego a reconstruirlos. Imagina a un artista hábil que dibuja un rostro de memoria y luego lo vuelve a dibujar perfectamente. Este proceso tiene dos partes principales.
Primero, un encoder toma una imagen de entrada, como un rostro. Comprime esta imagen en una representación más pequeña y abstracta. Este código comprimido captura las características clave del rostro. Segundo, un decoder toma ese código. Luego intenta reconstruir el rostro original a partir de él. La red se entrena comparando su reconstrucción con la original. Se ajusta constantemente para reducir errores.
Para crear un deepfake usando autoencoders, se entrenan dos autoencoders separados. Una red aprende de imágenes del Sujeto A. La otra aprende de imágenes del Sujeto B. Ambas redes usan el mismo encoder. Este encoder compartido aprende a extraer características faciales comunes. Se centra en aspectos como la posición de los ojos o la forma de la boca. Este conocimiento compartido se convierte en una conexión crucial.

A menudo llamado el "Padrino de la IA", el profesor Geoffrey Hinton es un psicólogo cognitivo y científico informático británico-canadiense. Su trabajo pionero en aprendizaje profundo, particularmente con redes neuronales en la Universidad de Toronto en 2006, sentó las bases cruciales para tecnologías como los deepfakes. (Fuente: web.cs.toronto.edu)
Luego, para el intercambio de rostros, el encoder procesa un fotograma de video del Sujeto A. Extrae las características faciales centrales. Este código extraído se introduce luego en el decoder del Sujeto B. El resultado es el rostro del Sujeto B, pero con las expresiones y movimientos de cabeza del Sujeto A. Este método fue innovador. Sin embargo, a menudo producía defectos evidentes como parpadeos o características desalineadas.
GANs: la revolución adversaria
Un gran avance en la creación de imágenes realistas se produjo en 2014. Ian Goodfellow, entonces estudiante de doctorado en la Universidad de Montreal, propuso las Generative Adversarial Networks, o GANs. Esto marcó un cambio significativo con respecto a los modelos generativos anteriores. Las GANs introdujeron un nuevo método de entrenamiento. Establecieron una competencia entre dos redes neuronales.
Imagina a un hábil falsificador de arte y a un astuto detective de arte. El falsificador crea pinturas falsas. El detective intenta identificarlas. Ambos mejoran con cada intento. Así es exactamente como funciona una GAN. Consiste en dos redes neuronales: un generador y un discriminador.
El generador actúa como el falsificador. Su trabajo es crear datos sintéticos. Para los deepfakes, genera imágenes o fotogramas de video realistas. Al principio, produce ruido aleatorio. Con el tiempo, aprende a copiar imágenes reales de su conjunto de datos de entrenamiento. Su objetivo es engañar al discriminador para que crea que sus creaciones son reales.
El discriminador es el detective. Recibe dos tipos de entrada. Algunas son imágenes reales de los datos de entrenamiento. Otras son imágenes falsas creadas por el generador. Su trabajo es etiquetar correctamente cada imagen como “real” o “falsa”. El discriminador proporciona retroalimentación al generador. Esta retroalimentación le indica al generador qué tan bien lo está haciendo.
Estas dos redes se entrenan al mismo tiempo en un proceso competitivo. El generador intenta mejorar sus falsificaciones. El discriminador intenta mejorar su detección. Esta competencia constante impulsa a ambas redes a mejorar. Finalmente, el generador logra crear imágenes sintéticas creíbles. Estas imágenes a menudo son difíciles de distinguir de las reales. Este entrenamiento adversario hizo que los deepfakes fueran mucho más realistas y sutiles de lo que los autoencoders podían lograr.

Ian Goodfellow, entonces estudiante de doctorado en la Universidad de Montreal, propuso las Generative Adversarial Networks (GANs) en 2014. Esta innovadora arquitectura de IA, que enfrenta a dos redes neuronales entre sí, avanzó significativamente la creación de imágenes sintéticas realistas y deepfakes. (Fuente: deeplearning.ai)
Perfeccionando el realismo: StyleGAN
Las primeras GANs eran potentes, pero aún tenían limitaciones. A veces les costaba controlar características específicas de la salida generada. Por ejemplo, era difícil cambiar el peinado de una persona sin alterar también su rostro. Sus creaciones también podían carecer de coherencia entre los fotogramas de video. El realismo, aunque mejorado, no siempre era perfecto.
En 2018, los investigadores de NVIDIA introdujeron StyleGAN. Esta arquitectura avanzó enormemente la tecnología GAN. StyleGAN permitió nuevos niveles de control sobre la generación de imágenes. Lo hizo añadiendo “estilos” en diferentes puntos de la red. Imagina separar una pintura en su composición, colores y pinceladas. StyleGAN permitió un control en capas similar.
StyleGAN añadió una “red de mapeo” y una capa de “normalización de instancia adaptativa” (AdaIN). La red de mapeo transforma una entrada aleatoria en un espacio oculto mejor organizado. Esto significa que diferentes partes del espacio controlan distintas características visuales. Las capas AdaIN luego añaden estos “estilos” al generador. Afectan rasgos visuales específicos. Por ejemplo, algunas capas podrían controlar características amplias como la pose o la forma general del rostro. Otras capas controlan detalles finos, como la textura de la piel o el color del cabello.
Este control en capas permitió a los investigadores crear imágenes increíblemente variadas y de alta calidad. Incluso podían cambiar atributos específicos sin afectar a otros. StyleGAN de NVIDIA, y sus versiones posteriores, produjeron resultados casi fotorrealistas. Esto amplió lo que era posible para los medios sintéticos. Hizo que los deepfakes fueran aún más difíciles de distinguir del contenido real. El rápido aumento de la potencia informática y los grandes conjuntos de datos también contribuyeron a este progreso. Los investigadores pudieron entrenar modelos más complejos con vastas cantidades de datos, lo que llevó a resultados más intrincados y convincentes.
El desafío de la detección: una carrera armamentista de IA
A medida que la tecnología deepfake mejoraba, los métodos de detección se volvieron cruciales. Investigadores y organizaciones reconocieron su potencial de uso indebido. Esto inició una “carrera armamentista” en la IA. Los creadores de deepfakes buscaban un realismo perfecto. Los detectores buscaban pistas sutiles en las falsificaciones.
Los primeros métodos de detección se centraron en defectos comunes. Estos incluían patrones de parpadeo inconsistentes o movimientos inusuales de la cabeza. Por ejemplo, los sujetos de deepfake a menudo no parpadeaban de forma natural. Esto se debía a que los conjuntos de datos de entrenamiento solían contener imágenes con los ojos abiertos. Investigadores de la Universidad de Albany encontraron estas diferencias. Publicaron sus hallazgos en un estudio de 2019.
La detección más avanzada ahora implica la forense digital. Estos sistemas buscan anomalías estadísticas en los medios generados. Analizan pequeñas inconsistencias a nivel de píxel. También examinan ligeras distorsiones en la geometría facial. Expertos como el Dr. Hany Farid, profesor en UC Berkeley, son especialistas en forense digital. Él afirma que debemos analizar señales sutiles. Estas señales incluyen iluminación inconsistente o sombras no coincidentes. Tales detalles son difíciles de reproducir perfectamente para los modelos de IA en toda una escena.
Empresas como Google y Facebook también han invertido mucho en la detección de deepfakes. Han lanzado desafíos para fomentar nuevas soluciones. El DeepFake Detection Dataset de Google, lanzado en 2019, proporcionó un gran conjunto de datos para los investigadores. Ayudó a entrenar modelos para identificar videos manipulados. La lucha continúa a medida que los creadores encuentran nuevas formas de ocultar sus rastros. Los métodos de detección deben cambiar constantemente para mantenerse al día. Esta lucha continua muestra cuán frágil puede ser la confianza digital.
El futuro de la realidad sintética
El viaje de la IA deepfake, desde los primeros autoencoders hasta los avanzados StyleGANs, continúa. Las capacidades de la tecnología crecen rápidamente. Ahora va más allá de los simples intercambios de rostros. Los investigadores están desarrollando herramientas para la creación de cuerpos completos y la copia de voz realista. Estos avances prometen grandes cambios en muchas áreas.
En el entretenimiento, los deepfakes podrían cambiar la forma en que se hacen las películas. Los actores podrían ser rejuvenecidos de forma fluida. Los personajes digitales podrían realizar acrobacias peligrosas sin riesgo. Empresas como Synthesia ya utilizan IA para crear avatares realistas para videos de capacitación corporativa. Esto reduce los costos y el tiempo de producción. Los usos son amplios. Incluyen marketing personalizado e incluso asistentes virtuales.
Sin embargo, las preocupaciones éticas siguen siendo significativas. El riesgo de desinformación, difamación y fraude de identidad es enorme. El Dr. Siwei Lyu, profesor de ciencias de la computación en la Universidad de Albany, advierte que esto daña la confianza social. Señala la creciente dificultad para distinguir la verdad de las mentiras. La facilidad para crear falsedades convincentes desafía la alfabetización mediática tradicional.
Gobiernos y legisladores están trabajando para encontrar formas de regular esta tecnología. Su objetivo es equilibrar la innovación con la seguridad pública. Esto incluye conversaciones sobre la marca de agua digital. También implica el seguimiento del origen del contenido multimedia. El futuro de la realidad sintética depende de este cuidadoso equilibrio. Necesita tanto nueva tecnología como buenas reglas.
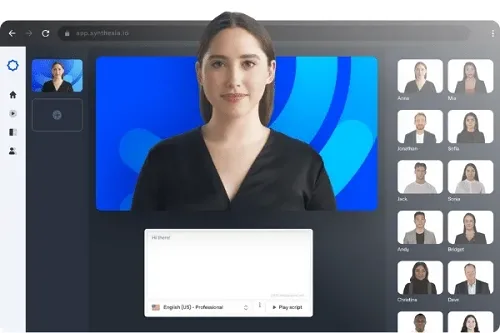
Synthesia es una empresa que utiliza IA avanzada para crear avatares humanos altamente realistas para videos de capacitación corporativa, marketing y otros contenidos digitales. Estos presentadores generados por IA demuestran las aplicaciones prácticas de la tecnología deepfake en la creación de realidad sintética. (Fuente: vidnoz.com)
Preguntas frecuentes
¿Cuál es la principal diferencia entre un autoencoder y una GAN? Un autoencoder aprende a comprimir y reconstruir datos usando una red. Una GAN utiliza dos redes que compiten: un generador que crea falsificaciones y un discriminador que las detecta. Este entrenamiento competitivo a menudo conduce a resultados más realistas.
¿Son todos los deepfakes dañinos? No. Aunque los deepfakes se hicieron conocidos por usos negativos, también tienen buenas aplicaciones. Estas incluyen la producción cinematográfica, recreaciones históricas y la accesibilidad del contenido para personas con discapacidades. El propósito detrás de su uso determina si son éticos.
¿Cuántos datos se necesitan para crear un buen deepfake? La cantidad de datos varía. Los primeros métodos de deepfake necesitaban miles de imágenes u horas de video. Las técnicas más nuevas, especialmente con el aprendizaje por transferencia (transfer learning), pueden crear falsificaciones creíbles con menos datos. Sin embargo, más datos de alta calidad generalmente resultan en deepfakes mejores y más consistentes.
¿Qué significa “deep” en deepfake? El término “deep” se refiere al aprendizaje profundo. Esta es una parte del aprendizaje automático. Utiliza redes neuronales con muchas capas. Estas redes a menudo se llaman “redes neuronales profundas” (deep neural networks). Ayudan a la IA a aprender patrones y características complejas a partir de los datos.
También te puede interesar:
👉 Bots en línea: El reto de detectar su suplantación en X y Facebook