
The 2017 Reddit Post That Unleashed Deepfake AI on the World
The shocking debut of deepfake AI in December 2017, when a Reddit user posted celebrity face-swapped videos, sparked a global debate.
Deepfakes: The Forger and the Detective
In December 2017, a Reddit user named “deepfakes” posted unsettling videos. These videos swapped celebrity faces onto adult film actresses. The effect was shocking and looked real for its time. This marked the public debut of synthetic media. It sparked a global debate about manipulated video.
These creations, soon called deepfakes, represented a significant advance in artificial intelligence. They blurred the line between genuine and fabricated reality. The underlying technology wasn’t entirely new. It built on decades of machine learning research. However, its widespread availability and high visual quality were novel.
Simply put, a deepfake uses AI to create realistic images, audio, or video. It replaces one person’s likeness with another’s. This often involves swapping faces or altering speech. The goal is to make the fake content appear authentic. This technology is now common. It influences everything from entertainment to misinformation campaigns.
Early days: autoencoders and the first swaps
The initial concepts for deepfakes started much earlier. Researchers explored how machines could learn from data. A key development occurred in 2006. Professor Geoffrey Hinton and his team at the University of Toronto introduced deep learning. This method used neural networks with many layers. It allowed computers to process complex patterns.
This early work led to a core deepfake tool: the autoencoder. An autoencoder is a type of neural network. It learns to compress data and then rebuild it. Imagine a skilled artist who sketches a face from memory and then redraws it perfectly. This process has two main parts.
First, an encoder takes an input image, such as a face. It compresses this image into a smaller, abstract representation. This compressed code captures the face’s key features. Second, a decoder takes that code. It then tries to reconstruct the original face from it. The network trains by comparing its reconstruction to the original. It constantly adjusts to reduce errors.
To create a deepfake using autoencoders, two separate autoencoders are trained. One network learns from images of Subject A. The other learns from images of Subject B. Both networks use the same encoder. This shared encoder learns to extract common facial features. It focuses on things like eye position or mouth shape. This shared knowledge becomes a crucial connection.

Often called the 'Godfather of AI,' Professor Geoffrey Hinton is a British-Canadian cognitive psychologist and computer scientist. His pioneering work in deep learning, particularly with neural networks at the University of Toronto in 2006, laid crucial groundwork for technologies like deepfakes. (Source: web.cs.toronto.edu)
Then, for face-swapping, the encoder processes a video frame of Subject A. It extracts the core facial features. This extracted code then goes into Subject B’s decoder. The result is Subject B’s face, but displaying Subject A’s expressions and head movements. This method was groundbreaking. However, it often produced clear flaws like flickering or misaligned features.
GANs: the adversarial revolution
A major step forward in creating realistic images came in 2014. Ian Goodfellow, then a PhD student at the University of Montreal, proposed Generative Adversarial Networks, or GANs. This marked a significant change from previous generative models. GANs introduced a new training method. They set up a competition between two neural networks.
Imagine a skilled art forger and a sharp art detective. The forger creates fake paintings. The detective tries to identify them. Both get better with each attempt. This is exactly how a GAN works. It consists of two neural networks: a generator and a discriminator.
The generator acts as the forger. Its job is to create synthetic data. For deepfakes, it generates realistic images or video frames. At first, it produces random noise. Over time, it learns to copy real images from its training dataset. Its goal is to trick the discriminator into believing its creations are real.
The discriminator is the detective. It receives two types of input. Some inputs are real images from the training data. Others are fake images made by the generator. Its job is to correctly label each image as either “real” or “fake.” The discriminator gives feedback to the generator. This feedback tells the generator how well it is doing.
These two networks train at the same time in a competitive process. The generator tries to improve its fakes. The discriminator tries to improve its detection. This constant competition pushes both networks to get better. Eventually, the generator becomes good at making believable synthetic images. These images are often hard to tell apart from real ones. This adversarial training made deepfakes much more realistic and subtle than autoencoders could.

Ian Goodfellow, then a PhD student at the University of Montreal, proposed Generative Adversarial Networks (GANs) in 2014. This groundbreaking AI architecture, which pits two neural networks against each other, significantly advanced the creation of realistic synthetic images and deepfakes. (Source: deeplearning.ai)
Refining realism: StyleGAN
Early GANs were powerful, but they still had limitations. They sometimes struggled to control specific features of the generated output. For example, it was hard to change a person’s hairstyle without also changing their face. Their creations could also lack consistency across video frames. The realism, though improved, was not always perfect.
In 2018, NVIDIA researchers introduced StyleGAN. This architecture greatly advanced GAN technology. StyleGAN allowed new levels of control over image generation. It did this by adding “styles” at different points in the network. Imagine separating a painting into its composition, colors, and brushstrokes. StyleGAN enabled similar layered control.
StyleGAN added a “mapping network” and an “adaptive instance normalization” (AdaIN) layer. The mapping network changes a random input into a better-organized hidden space. This means different parts of the space control different visual features. The AdaIN layers then add these “styles” into the generator. They affect specific visual traits. For instance, some layers might control broad features like pose or general facial shape. Other layers control fine details, such as skin texture or hair color.
This layered control allowed researchers to create incredibly varied and high-quality images. They could even change specific attributes without affecting others. NVIDIA’s StyleGAN, and its later versions, produced almost photorealistic results. This expanded what was possible for synthetic media. It made deepfakes even harder to tell from real content. The quick increase in computing power and large datasets also helped this progress. Researchers could train more complex models on vast amounts of data, leading to more intricate and convincing results.
The detection challenge: an AI arms race
As deepfake technology improved, detection methods became crucial. Researchers and organizations recognized its potential for misuse. This started an “arms race” in AI. Deepfake creators aimed for perfect realism. Detectors searched for subtle clues in the fakes.
Early detection methods focused on common faults. These included inconsistent blinking patterns or unusual head movements. For example, deepfake subjects often did not blink naturally. This was because training datasets usually contained images with open eyes. Researchers at the University at Albany found these differences. They published their findings in a 2019 study.
More advanced detection now involves AI forensics. These systems look for statistical oddities in the generated media. They analyze tiny inconsistencies at the pixel level. They also examine slight distortions in facial geometry. Experts like Dr. Hany Farid, a professor at UC Berkeley, are digital forensics specialists. He states we must analyze subtle signs. These signs include inconsistent lighting or unmatched shadows. Such details are hard for AI models to perfectly reproduce throughout a whole scene.
Companies like Google and Facebook have also invested heavily in deepfake detection. They have launched challenges to encourage new solutions. Google’s DeepFake Detection Dataset, released in 2019, provided a large dataset for researchers. It helped train models to identify manipulated videos. The struggle continues as creators find new ways to hide their tracks. Detection methods must constantly change to keep up. This ongoing fight shows how fragile digital trust can be.
Synthetic reality’s future
The journey of deepfake AI, from early autoencoders to advanced StyleGANs, continues. The technology’s abilities grow quickly. It now goes beyond simple face swaps. Researchers are developing tools for full body creation and realistic voice copying. These advances promise big changes across many areas.
In entertainment, deepfakes could change how films are made. Actors might be smoothly de-aged. Digital characters could perform dangerous stunts without risk. Companies like Synthesia already use AI to create realistic avatars for corporate training videos. This lowers production costs and time. The uses are wide-ranging. They include personalized marketing and even virtual assistants.
However, the ethical concerns remain significant. The risk of misinformation, defamation, and identity fraud is huge. Dr. Siwei Lyu, a computer science professor at the University at Albany, warns this harms societal trust. He points out the growing difficulty in distinguishing truth from lies. The ease of creating convincing falsehoods challenges traditional media literacy.
Governments and policymakers are working to find ways to regulate this technology. They aim to balance innovation with public safety. This includes talks about digital watermarking. It also involves tracking the origin of media content. The future of synthetic reality depends on this careful balance. It needs both new technology and good rules.
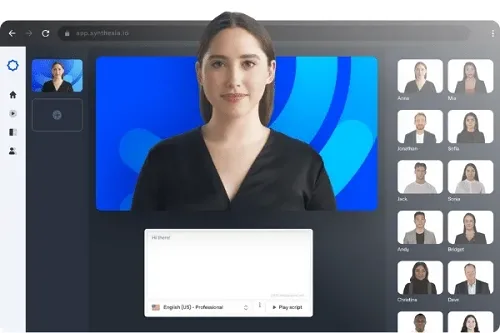
Synthesia is a company that uses advanced AI to create highly realistic human avatars for corporate training videos, marketing, and other digital content. These AI-generated presenters demonstrate the practical applications of deepfake technology in creating synthetic reality. (Source: vidnoz.com)
FAQ
What is the main difference between an autoencoder and a GAN? An autoencoder learns to compress and rebuild data using one network. A GAN uses two competing networks: a generator that makes fakes and a discriminator that spots them. This competitive training often leads to more realistic results.
Are all deepfakes harmful? No. While deepfakes became known for bad uses, they also have good applications. These include film production, historical reenactments, and making content accessible for people with disabilities. The purpose behind their use determines if they are ethical.
How much data is needed to create a good deepfake? The amount of data varies. Early deepfake methods needed thousands of images or hours of video. Newer techniques, especially with transfer learning, can create believable fakes with less data. However, more high-quality data generally results in better, more consistent deepfakes.
What does the “deep” in deepfake mean? The “deep” refers to deep learning. This is a part of machine learning. It uses neural networks with many layers. These networks are often called “deep neural networks.” They help the AI learn complex patterns and features from data.
You might also like:
👉 Unmasking Online Bots: The X & Facebook Mimicry Challenge
👉 Predicting Stock Market Trends: ML & Sentiment Analysis Guide