
Deepfakes: 2017, quand Reddit a fait basculer la réalité numérique
En décembre 2017, des vidéos troublantes postées sur Reddit ont révélé au monde la puissance des deepfakes. Cette technologie d'IA a instantanément déclenché un débat mondial sur la manipulation vidéo, brouillant la frontière entre le vrai et le faux.
Deepfakes : le faussaire et le détective
En décembre 2017, un utilisateur de Reddit nommé “deepfakes” a publié des vidéos troublantes. Ces vidéos superposaient les visages de célébrités sur ceux d’actrices de films pour adultes. L’effet était choquant et son réalisme, saisissant pour l’époque. Cela a marqué l’apparition publique des médias synthétiques. Cela a déclenché un débat mondial sur la manipulation vidéo.
Ces créations, bientôt appelées deepfakes, représentaient une avancée significative en intelligence artificielle. Elles ont brouillé la frontière entre la réalité authentique et la réalité fabriquée. La technologie sous-jacente n’était pas entièrement nouvelle. Elle s’appuyait sur des décennies de recherche en apprentissage automatique. Cependant, sa disponibilité généralisée et sa haute qualité visuelle étaient inédites.
En termes simples, un deepfake utilise l’IA pour créer des images, de l’audio ou des vidéos réalistes. Il remplace les traits d’une personne par ceux d’une autre. Cela implique souvent l’échange de visages ou la modification de la parole. L’objectif est de faire en sorte que le contenu falsifié paraisse authentique. Cette technologie est désormais courante. Elle influence tout, du divertissement aux campagnes de désinformation.
Les débuts : les auto-encodeurs et les premiers échanges
Les concepts initiaux des deepfakes remontent à bien plus longtemps. Les chercheurs ont exploré comment les machines pouvaient apprendre à partir de données. Un développement clé a eu lieu en 2006. Le professeur Geoffrey Hinton et son équipe de l’Université de Toronto ont introduit le deep learning. Cette méthode utilisait des réseaux neuronaux à plusieurs couches. Elle a permis aux ordinateurs de traiter des motifs complexes.
Ces premiers travaux ont conduit à un outil essentiel des deepfakes : l’auto-encodeur. Un auto-encodeur est un type de réseau neuronal. Il apprend à compresser des données puis à les reconstruire. Imaginez un artiste talentueux qui esquisse un visage de mémoire puis le redessine parfaitement. Ce processus comporte deux parties principales.
Premièrement, un encodeur prend une image en entrée, comme un visage. Il compresse cette image en une représentation plus petite et abstraite. Ce code compressé capture les caractéristiques clés du visage. Deuxièmement, un décodeur prend ce code. Il essaie ensuite de reconstruire le visage original à partir de celui-ci. Le réseau s’entraîne en comparant sa reconstruction à l’original. Il s’ajuste constamment pour réduire les erreurs.
Pour créer un deepfake à l’aide d’auto-encodeurs, deux auto-encodeurs distincts sont entraînés. Un réseau apprend à partir d’images du Sujet A. L’autre apprend à partir d’images du Sujet B. Les deux réseaux utilisent le même encodeur. Cet encodeur partagé apprend à extraire des caractéristiques faciales communes. Il se concentre sur des éléments tels que la position des yeux ou la forme de la bouche. Cette connaissance partagée devient une connexion cruciale.

Souvent appelé le 'Parrain de l'IA', le professeur Geoffrey Hinton est un psychologue cognitif et informaticien britanno-canadien. Ses travaux pionniers en deep learning, notamment avec les réseaux neuronaux à l'Université de Toronto en 2006, ont jeté les bases cruciales de technologies comme les deepfakes. (Source : web.cs.toronto.edu)
Ensuite, pour l’échange de visages, l’encodeur traite une trame vidéo du Sujet A. Il en extrait les caractéristiques faciales principales. Ce code extrait est ensuite transmis au décodeur du Sujet B. Le résultat est le visage du Sujet B, mais avec les expressions et les mouvements de tête du Sujet A. Cette méthode était révolutionnaire. Cependant, elle produisait souvent des imperfections flagrantes comme des scintillements ou des traits mal alignés.
Les GAN : la révolution antagoniste
Une avancée majeure dans la création d’images réalistes est survenue en 2014. Ian Goodfellow, alors doctorant à l’Université de Montréal, a proposé les réseaux antagonistes génératifs, ou GAN. Cela a marqué un changement significatif par rapport aux modèles génératifs précédents. Les GAN ont introduit une nouvelle méthode d’entraînement. Ils ont mis en place une compétition entre deux réseaux neuronaux.
Imaginez un faussaire d’art talentueux et un détective d’art perspicace. Le faussaire crée de faux tableaux. Le détective essaie de les identifier. Les deux s’améliorent à chaque tentative. C’est exactement ainsi que fonctionne un GAN. Il se compose de deux réseaux neuronaux : un générateur et un discriminateur.
Le générateur agit comme le faussaire. Son travail est de créer des données synthétiques. Pour les deepfakes, il génère des images ou des trames vidéo réalistes. Au début, il produit du bruit aléatoire. Avec le temps, il apprend à copier des images réelles à partir de son ensemble de données d’entraînement. Son objectif est de tromper le discriminateur en lui faisant croire que ses créations sont réelles.
Le discriminateur est le détective. Il reçoit deux types d’entrées. Certaines entrées sont des images réelles provenant des données d’entraînement. D’autres sont des images fausses créées par le générateur. Son travail est de classifier correctement chaque image comme “réelle” ou “fausse”. Le discriminateur fournit un feedback au générateur. Ce feedback indique au générateur son degré de réussite.
Ces deux réseaux s’entraînent simultanément dans un processus compétitif. Le générateur essaie d’améliorer ses contrefaçons. Le discriminateur essaie d’améliorer sa détection. Cette compétition constante pousse les deux réseaux à s’améliorer. Finalement, le générateur devient performant dans la création d’images synthétiques crédibles. Ces images sont souvent difficiles à distinguer des vraies. Cet entraînement antagoniste a rendu les deepfakes beaucoup plus réalistes et subtils que ne le permettaient les auto-encodeurs.

Ian Goodfellow, alors doctorant à l'Université de Montréal, a proposé les réseaux antagonistes génératifs (GAN) en 2014. Cette architecture d'IA révolutionnaire, qui oppose deux réseaux neuronaux l'un à l'autre, a considérablement fait progresser la création d'images synthétiques réalistes et de deepfakes. (Source : deeplearning.ai)
Affiner le réalisme : StyleGAN
Les premiers GAN étaient puissants, mais ils avaient encore des limites. Ils avaient parfois du mal à contrôler des caractéristiques spécifiques du résultat généré. Par exemple, il était difficile de changer la coiffure d’une personne sans également modifier son visage. Leurs créations pouvaient également manquer de cohérence entre les trames vidéo. Le réalisme, bien qu’amélioré, n’était pas toujours parfait.
En 2018, les chercheurs de NVIDIA ont introduit StyleGAN. Cette architecture a considérablement fait progresser la technologie GAN. StyleGAN a permis de nouveaux niveaux de contrôle sur la génération d’images. Il y est parvenu en ajoutant des “styles” à différents points du réseau. Imaginez séparer une peinture en sa composition, ses couleurs et ses coups de pinceau. StyleGAN a permis un contrôle en couches similaire.
StyleGAN a ajouté un “mapping network” et une couche de “adaptive instance normalization” (AdaIN). Le mapping network transforme une entrée aléatoire en un espace latent mieux organisé. Cela signifie que différentes parties de cet espace contrôlent différentes caractéristiques visuelles. Les couches AdaIN ajoutent ensuite ces “styles” au générateur. Elles affectent des traits visuels spécifiques. Par exemple, certaines couches peuvent contrôler des caractéristiques générales comme la pose ou la forme générale du visage. D’autres couches contrôlent les détails fins, tels que la texture de la peau ou la couleur des cheveux.
Ce contrôle en couches a permis aux chercheurs de créer des images incroyablement variées et de haute qualité. Ils pouvaient même modifier des attributs spécifiques sans affecter les autres. Le StyleGAN de NVIDIA, et ses versions ultérieures, ont produit des résultats presque photoréalistes. Cela a élargi les possibilités des médias synthétiques. Cela a rendu les deepfakes encore plus difficiles à distinguer du contenu réel. L’augmentation rapide de la puissance de calcul et des grands ensembles de données a également contribué à ce progrès. Les chercheurs ont pu entraîner des modèles plus complexes sur de vastes quantités de données, ce qui a conduit à des résultats plus complexes et convaincants.
Le défi de la détection : une course aux armements de l’IA
À mesure que la technologie des deepfakes s’améliorait, les méthodes de détection sont devenues cruciales. Les chercheurs et les organisations ont reconnu son potentiel d’utilisation abusive. Cela a déclenché une “course aux armements” dans le domaine de l’IA. Les créateurs de deepfakes visaient un réalisme parfait. Les détecteurs recherchaient des indices subtils dans les contrefaçons.
Les premières méthodes de détection se sont concentrées sur les défauts courants. Celles-ci incluaient des clignements d’yeux irréguliers ou des mouvements de tête inhabituels. Par exemple, les sujets de deepfake ne clignaient souvent pas naturellement des yeux. Cela était dû au fait que les ensembles de données d’entraînement contenaient généralement des images avec les yeux ouverts. Des chercheurs de l’Université d’Albany ont identifié ces différences. Ils ont publié leurs découvertes dans une étude de 2019.
La détection plus avancée implique désormais la forensique numérique basée sur l’IA. Ces systèmes recherchent des anomalies statistiques dans les médias générés. Ils analysent de minuscules incohérences au niveau des pixels. Ils examinent également de légères distorsions dans la géométrie faciale. Des experts comme le Dr Hany Farid, professeur à l’UC Berkeley, sont des spécialistes de la criminalistique numérique. Il affirme que nous devons analyser des signes subtils. Ces signes incluent un éclairage incohérent ou des ombres incohérentes. De tels détails sont difficiles à reproduire parfaitement pour les modèles d’IA tout au long d’une scène entière.
Des entreprises comme Google et Facebook ont également beaucoup investi dans la détection des deepfakes. Elles ont lancé des défis pour encourager de nouvelles solutions. Le DeepFake Detection Dataset de Google, publié en 2019, a fourni un grand ensemble de données aux chercheurs. Il a aidé à entraîner des modèles à identifier les vidéos manipulées. La lutte continue alors que les créateurs trouvent de nouvelles façons de cacher leurs traces. Les méthodes de détection doivent constamment évoluer pour s’adapter. Cette lutte continue montre à quel point la confiance numérique peut être fragile.
L’avenir de la réalité synthétique
Le parcours de l’IA deepfake, des premiers auto-encodeurs aux StyleGAN avancés, se poursuit. Les capacités de la technologie augmentent rapidement. Elle va désormais au-delà des simples échanges de visages. Les chercheurs développent des outils pour la création de corps entiers et la copie de voix réalistes. Ces avancées promettent de grands changements dans de nombreux domaines.
Dans le divertissement, les deepfakes pourraient changer la façon dont les films sont réalisés. Les acteurs pourraient être rajeunis de façon imperceptible. Des personnages numériques pourraient réaliser des cascades dangereuses sans risque. Des entreprises comme Synthesia utilisent déjà l’IA pour créer des avatars réalistes pour les vidéos de formation d’entreprise. Cela réduit les coûts et le temps de production. Les utilisations sont très variées. Elles incluent le marketing personnalisé et même les assistants virtuels.
Cependant, les préoccupations éthiques restent importantes. Le risque de désinformation, de diffamation et de fraude à l’identité est considérable. Le Dr Siwei Lyu, professeur d’informatique à l’Université d’Albany, avertit que cela nuit à la confiance sociétale. Il souligne la difficulté croissante à distinguer la vérité du mensonge. La facilité de créer des mensonges convaincants remet en question l’éducation aux médias traditionnelle.
Les gouvernements et les décideurs politiques travaillent à trouver des moyens de réglementer cette technologie. Ils visent à équilibrer l’innovation et la sécurité publique. Cela inclut des discussions sur le filigrane numérique. Cela implique également le suivi de l’origine du contenu médiatique. L’avenir de la réalité synthétique dépend de cet équilibre délicat. Il nécessite à la fois de nouvelles technologies et de bonnes règles.
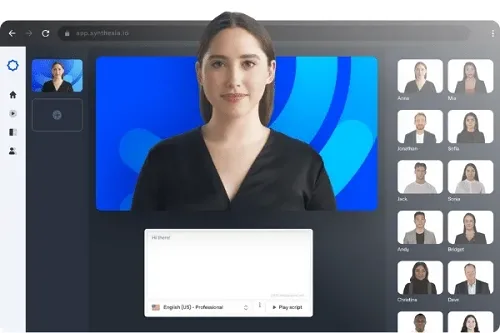
Synthesia est une entreprise qui utilise l'IA avancée pour créer des avatars humains très réalistes pour les vidéos de formation d'entreprise, le marketing et d'autres contenus numériques. Ces présentateurs générés par l'IA démontrent les applications pratiques de la technologie deepfake dans la création de réalité synthétique. (Source : vidnoz.com)
FAQ
Quelle est la principale différence entre un auto-encodeur et un GAN ? Un auto-encodeur apprend à compresser et à reconstruire des données à l’aide d’un seul réseau. Un GAN utilise deux réseaux concurrents : un générateur qui génère des faux et un discriminateur qui les détecte. Cet entraînement compétitif conduit souvent à des résultats plus réalistes.
Tous les deepfakes sont-ils nuisibles ? Non. Bien que les deepfakes soient devenus connus pour leurs utilisations malveillantes, ils ont aussi de bonnes applications. Celles-ci incluent la production cinématographique, les reconstitutions historiques et la mise à disposition de contenu pour les personnes handicapées. Le but de leur utilisation détermine s’ils sont éthiques.
Combien de données sont nécessaires pour créer un bon deepfake ? La quantité de données varie. Les premières méthodes de deepfake nécessitaient des milliers d’images ou des heures de vidéo. Les techniques plus récentes, notamment avec l’apprentissage par transfert, peuvent générer des faux crédibles avec moins de données. Cependant, des données de meilleure qualité conduisent généralement à des deepfakes de meilleure qualité et plus cohérents.
Que signifie le “deep” dans deepfake ? Le “deep” fait référence au deep learning (apprentissage profond). C’est une partie de l’apprentissage automatique. Il utilise des réseaux neuronaux à plusieurs couches. Ces réseaux sont souvent appelés “réseaux neuronaux profonds”. Ils aident l’IA à apprendre des motifs et des caractéristiques complexes à partir des données.
Vous pourriez aussi aimer:
👉 Démasquer les bots en ligne : le défi du mimétisme sur X et Facebook